
Robot công nghiệp
Robot học tăng cường (Reinforcement Learning for robots): “Tự học” để làm chủ thế giới thực

Robot công nghiệp đã thay đổi căn bản ngành sản xuất công nghiệp, nâng cao năng suất và chất lượng sản phẩm thông qua tự động hóa sản xuất công nghiệp. Tuy nhiên, để đáp ứng yêu cầu của Nhà máy thông minh và Công nghiệp 4.0, robot cần vượt qua giới hạn lập trình cứng nhắc, thích ứng linh hoạt với môi trường biến đổi và thực hiện các tác vụ phức tạp. Năng lực “tự học” để tối ưu hóa hành vi trong thế giới thực trở thành yêu cầu cấp thiết. Chính vì vậy, Học tăng cường (Reinforcement Learning – RL), một nhánh đột phá của Trí tuệ nhân tạo (AI), đang mở ra kỷ nguyên mới cho robot. Học tăng cường cho phép robot học cách đưa ra quyết định tối ưu thông qua cơ chế “thử và sai” được dẫn dắt bởi “phần thưởng” và “hình phạt”, tương tự cách con người học từ kinh nghiệm.
Robot học tăng cường không chỉ tăng cường đáng kể khả năng tự chủ và linh hoạt, mà còn mở ra những tiềm năng ứng dụng chưa từng có trong sản xuất công nghiệp, từ gắp đặt vật thể ngẫu nhiên đến tối ưu hóa toàn bộ dây chuyền sản xuất tự động và bảo trì dự đoán. Bài viết này sẽ đi sâu vào định nghĩa và cách thức hoạt động của Robot học tăng cường, các thuật toán chính, ứng dụng cụ thể trong robot công nghiệp, tầm quan trọng chiến lược, cùng với các thách thức và xu hướng phát triển tương lai.
1. Robot học tăng cường (Reinforcement Learning for robots) là gì?
Robot học tăng cường (Reinforcement Learning for robots) đặc trưng cho việc áp dụng các thuật toán Học tăng cường (Reinforcement Learning – RL) nhằm huấn luyện robot học cách hành động tối ưu trong một môi trường cụ thể để đạt được một mục tiêu đã định, thông qua quá trình tương tác liên tục và nhận phản hồi từ môi trường đó. Phương pháp này đại diện cho một sự chuyển đổi paradigm so với các cách tiếp cận lập trình truyền thống hoặc Học có giám sát, bởi vì thay vì được “dạy” một cách trực tiếp với các cặp dữ liệu đầu vào-đầu ra được gán nhãn, robot tự khám phá các chiến lược hành động tốt nhất bằng cách thực hiện “thử và sai” có hệ thống.
Trong quá trình này, robot sẽ nhận được “phần thưởng” (reward) khi thực hiện các hành động có lợi hoặc đưa nó đến gần mục tiêu, và nhận “hình phạt” (penalty) khi mắc lỗi hoặc thực hiện các hành động không mong muốn. Mục tiêu cuối cùng của robot là tối đa hóa tổng “phần thưởng” mà nó tích lũy được theo thời gian, dẫn đến việc hình thành các hành vi thông minh, thích nghi và hiệu quả cao trong môi trường hoạt động của nó, từ đó tối ưu hóa năng suất và giảm thiểu chi phí.

1.1. Cách thức hoạt động của Robot học tăng cường
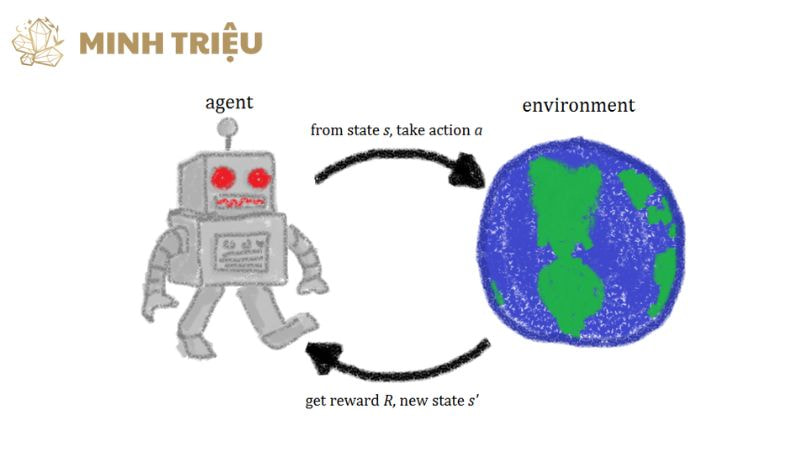
Robot học tăng cường hoạt động dựa trên một khung lý thuyết rõ ràng, tập trung vào sự tương tác động giữa “tác nhân” (agent) và “môi trường” (environment) để học hỏi và cải thiện hành vi của mình theo thời gian.
Mô hình tác nhân-môi trường là cốt lõi của Học tăng cường, miêu tả mối quan hệ qua lại giữa robot (đóng vai trò là “tác nhân”) và thế giới bên ngoài mà nó tương tác (“môi trường”). Tại mỗi bước thời gian, tác nhân quan sát “trạng thái” (state) hiện tại của môi trường, thu thập thông tin từ các cảm biến (ví dụ: cảm biến lực, thị giác máy) hoặc hệ thống điều khiển nội bộ.
Dựa trên trạng thái này, tác nhân sau đó thực hiện một “hành động” (action) được lựa chọn theo “chiến lược” hiện tại của mình, ví dụ như di chuyển khớp robot, gắp đặt một vật thể, hoặc điều chỉnh tốc độ của dây chuyền sản xuất tự động. Hành động này sẽ tác động lên môi trường, khiến môi trường chuyển sang một trạng thái mới. Đồng thời, tác nhân nhận được một “phần thưởng” (reward) hoặc “hình phạt” từ môi trường, một tín hiệu phản hồi định lượng mức độ tốt hay xấu của hành động đó đối với mục tiêu đã định.
Hàm phần thưởng là một yếu tố then chốt, định nghĩa và định lượng mức độ mong muốn của các hành động được thực hiện bởi robot, qua đó hướng dẫn toàn bộ quá trình học một cách có mục tiêu. Hàm này gán một giá trị số cho mỗi hành động mà robot thực hiện trong một trạng thái cụ thể; “phần thưởng” dương khuyến khích các hành động mong muốn và có lợi cho việc đạt mục tiêu (ví dụ: lắp ráp thành công một bộ phận, giảm thời gian chu kỳ sản xuất, tránh va chạm), trong khi “phần thưởng” âm (hoặc “hình phạt”) trừng phạt các hành động không mong muốn hoặc có hại (ví dụ: làm rơi vật thể, va chạm với robot khác hoặc con người, tăng chi phí năng lượng), giúp robot tránh lặp lại sai lầm và tối ưu hóa hiệu suất. Việc thiết kế hàm phần thưởng hiệu quả là rất quan trọng để đảm bảo robot học được hành vi tối ưu mong muốn, phù hợp với mục tiêu của sản xuất công nghiệp.
Chiến lược (Policy) là yếu tố cuối cùng mà robot cần học, đại diện cho một tập hợp các quy tắc hoặc ánh xạ từ trạng thái của môi trường đến hành động cần thực hiện. Mục tiêu của quá trình Học tăng cường là để robot học được một chiến lược tối ưu, tức là một tập hợp các quy tắc hành động đảm bảo rằng nó sẽ tối đa hóa tổng “phần thưởng” tích lũy được theo thời gian khi tương tác với môi trường. Chiến lược này có thể là deterministic (cho một trạng thái cụ thể, luôn có một hành động cụ thể) hoặc stochastic (cho một trạng thái, có một phân phối xác suất cho các hành động), và nó là biểu hiện cuối cùng của “trí tuệ” mà robot đã học được, cho phép nó hoạt động tự chủ và hiệu quả trong các kịch bản thực tế.
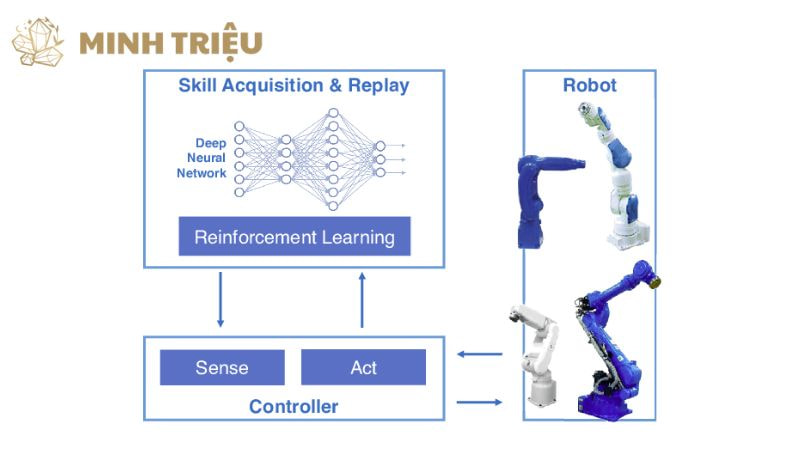
2. Các thuật toán và kỹ thuật chính trong Robot học tăng cường
Để hiện thực hóa khả năng “tự học” của robot trong môi trường đa dạng của sản xuất công nghiệp, lĩnh vực Học tăng cường đã phát triển nhiều thuật toán và kỹ thuật khác nhau, mỗi loại có ưu điểm và ứng dụng riêng biệt trong việc điều khiển và tối ưu hóa hành vi của robot.
Q-learning là một thuật toán Học tăng cường kinh điển và dựa trên giá trị, hoạt động bằng cách học một hàm Q (Q-function) ước tính giá trị tối đa của việc thực hiện một hành động cụ thể trong một trạng thái cụ thể, sau đó theo dõi chiến lược tối ưu. Hàm Q này biểu thị tổng “phần thưởng” tích lũy mà robot có thể nhận được trong tương lai nếu nó thực hiện hành động đó trong trạng thái hiện tại và sau đó tuân theo một chiến lược tối ưu.
Thuật toán này thích hợp cho các môi trường có không gian trạng thái và hành động rời rạc, không quá lớn, ví dụ như bài toán tìm đường đi ngắn nhất trên lưới. Ứng dụng trong robot bao gồm điều khiển robot gắp vật thể đơn giản trong môi trường có cấu trúc cố định, hoặc điều hướng robot di động tự hành (AGV/AMR) tránh chướng ngại vật trong các không gian hạn chế và đã biết trước.
Deep Q-Network (DQN) là một cải tiến đáng kể của Q-learning, ra đời để khắc phục hạn chế về không gian trạng thái lớn hoặc liên tục bằng cách kết hợp khả năng của Q-learning với sức mạnh biểu diễn của mạng nơ-ron sâu (Deep Neural Network). Bằng cách sử dụng mạng nơ-ron sâu để xấp xỉ hàm Q, DQN cho phép robot học từ các trạng thái biểu diễn phức tạp như hình ảnh từ thị giác máy hoặc dữ liệu cảm biến thô, mà các phương pháp Q-learning truyền thống không thể xử lý hiệu quả. Ứng dụng trong robot rất đa dạng, từ điều khiển robot trong môi trường 3D phức tạp với nhiều vật cản động, đến các tác vụ lắp ráp đòi hỏi nhận diện hình ảnh chính xác và điều khiển tinh tế, hoặc thậm chí điều khiển robot thực hiện các hành vi phức tạp trong môi trường ảo trước khi triển khai vào thế giới thực (Sim-to-Real).
Policy Gradient Methods (Ví dụ: REINFORCE, A2C, PPO) là một nhóm các thuật toán Học tăng cường tập trung vào việc học trực tiếp chiến lược (policy) của robot thay vì học hàm giá trị như Q-learning. Các phương pháp này trực tiếp tối ưu hóa các tham số của chiến lược để tăng xác suất thực hiện các hành động mang lại “phần thưởng” cao. Chúng thường hiệu quả hơn và ổn định hơn trong các môi trường có không gian hành động liên tục và phức tạp, nơi việc xấp xỉ hàm Q trở nên khó khăn.

Ứng dụng trong robot bao gồm điều khiển robot thực hiện các chuyển động phức tạp và mượt mà như đi bộ, chạy, hoặc các tác vụ đòi hỏi sự khéo léo và điều khiển khớp robot chính xác trong các ứng dụng như gia công máy, hàn hồ quang, hoặc điều khiển robot để chơi các trò chơi đòi hỏi kỹ năng vận động tinh xảo. Actor-Critic Methods (Ví dụ: DDPG, TD3, SAC) là một lớp thuật toán kết hợp ưu điểm của cả phương pháp học chiến lược (actor) và học hàm giá trị (critic) để đạt được hiệu suất tốt hơn và hội tụ nhanh hơn. “Actor” học chiến lược tối ưu, quyết định hành động nào cần thực hiện trong một trạng thái cụ thể. Trong khi đó, “critic” học một hàm giá trị để đánh giá chất lượng của các hành động do actor thực hiện, cung cấp phản hồi quan trọng cho việc cập nhật chiến lược của actor.
Sự kết hợp này giúp ổn định quá trình học và cải thiện hiệu quả khám phá môi trường. Ứng dụng trong robot rất phong phú, bao gồm điều khiển robot trong các tác vụ đòi hỏi sự chính xác và tốc độ cao như gắp đặt linh kiện điện tử nhỏ, lắp ráp phức tạp với các end-effectors chuyên dụng, hoặc điều khiển robot để thực hiện các thao tác tinh tế trên dây chuyền sản xuất tự động đòi hỏi phản ứng nhanh và linh hoạt.
Imitation Learning (Ví dụ: Behavior Cloning, DAgger) là một kỹ thuật mà robot học bằng cách bắt chước hành vi của một người hướng dẫn hoặc một chuyên gia con người, thường được sử dụng để khởi động quá trình học Học tăng cường hoặc xử lý các tác vụ khó học từ đầu. Thay vì khám phá thông qua thử và sai hoàn toàn, robot được cung cấp các cặp dữ liệu “quan sát-hành động” từ người hướng dẫn và học một ánh xạ trực tiếp từ trạng thái quan sát đến hành động tương ứng.
Kỹ thuật này giúp nhanh chóng “tiêm” kiến thức ban đầu vào robot, đặc biệt hữu ích khi việc thiết kế hàm phần thưởng phức tạp hoặc khi quá trình khám phá trong thế giới thực quá nguy hiểm/tốn kém. Ứng dụng trong robot bao gồm dạy robot các kỹ năng cơ bản (ví dụ: cách cầm nắm một dụng cụ), điều khiển robot trong các tác vụ có sự can thiệp của con người, hoặc huấn luyện cobots để phản ứng theo cách an toàn và tự nhiên trong môi trường làm việc chung với con người, góp phần đảm bảo an toàn lao động và hiệu quả hợp tác.
Inverse Reinforcement Learning (IRL) là một phương pháp mà robot học hàm phần thưởng ẩn từ hành vi quan sát được của người hướng dẫn hoặc chuyên gia, thay vì được cung cấp hàm phần thưởng rõ ràng và được thiết kế thủ công. Mục tiêu là suy luận ra “ý định” hoặc “mục tiêu” của người hướng dẫn từ cách họ thực hiện một tác vụ, đặc biệt hữu ích khi việc định nghĩa hàm phần thưởng trực tiếp là khó hoặc không trực quan. Sau khi học được hàm phần thưởng, robot sẽ sử dụng các thuật toán Học tăng cường thông thường để tối ưu hóa hành vi của mình nhằm tối đa hóa hàm phần thưởng đã suy luận.
Ứng dụng trong robot bao gồm dạy robot các hành vi phức tạp hoặc tinh tế mà việc định nghĩa hàm phần thưởng trực tiếp là khó khăn, điều khiển robot trong các tác vụ có nhiều mục tiêu không rõ ràng, hoặc giúp robot hiểu được ý định của con người trong các kịch bản tương tác để thực hiện các nhiệm vụ phức tạp hơn một cách tự nhiên và hiệu quả.
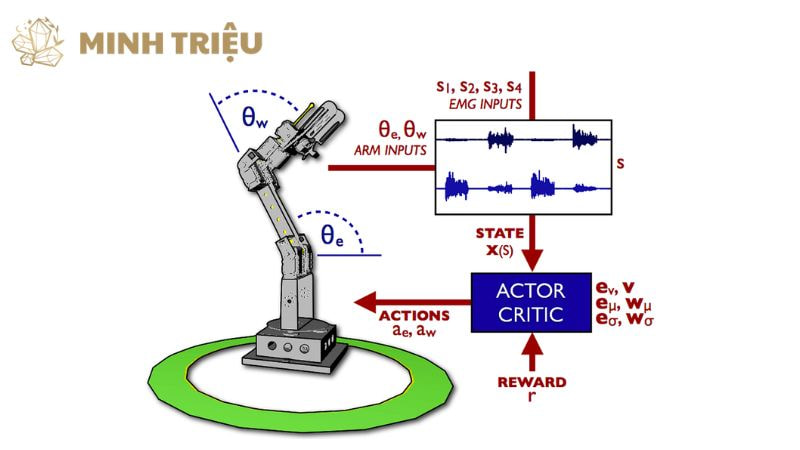
3. Các ứng dụng cụ thể của Robot học tăng cường trong sản xuất công nghiệp
Robot học tăng cường đang tạo ra những bước đột phá đáng kể trong lĩnh vực sản xuất công nghiệp, cho phép robot thực hiện các tác vụ phức tạp và linh hoạt hơn, từ đó góp phần vào sự phát triển của Nhà máy thông minh và nâng cao hiệu quả tổng thể của dây chuyền sản xuất tự động.
Điều khiển Robot linh hoạt và thích ứng là một trong những ứng dụng nổi bật nhất, giúp robot vượt qua giới hạn của các chương trình cố định và đáp ứng hiệu quả với các biến động trong môi trường thực tế. Robot học cách điều khiển các khớp robot và end-effectors (bộ phận cuối cánh tay robot) một cách tinh vi để thực hiện các tác vụ phức tạp như gắp đặt vật thể có hình dạng khác nhau, vị trí không xác định trong môi trường lộn xộn (ví dụ: gắp chi tiết từ thùng ngẫu nhiên – bin picking), lắp ráp các bộ phận với dung sai cực kỳ chặt chẽ đòi hỏi lực điều khiển chính xác, hoặc thực hiện các thao tác đòi hỏi sự khéo léo và tương tác lực nhạy bén như mài, đánh bóng các bề mặt không đều hoặc lắp cáp.
Lợi ích của việc này là tăng đáng kể tính linh hoạt và khả năng thích ứng của robot, cho phép chúng làm việc hiệu quả trong môi trường không có cấu trúc hoặc thay đổi liên tục, giảm sự phụ thuộc vào việc sắp xếp chính xác vật liệu đầu vào và tối ưu hóa quy trình sản xuất.
Tối ưu hóa đường đi và điều hướng là một ứng dụng quan trọng khác, cho phép robot di chuyển hiệu quả và an toàn hơn trong môi trường sản xuất năng động và thường xuyên thay đổi. Robot học cách tìm đường đi tối ưu nhất trong môi trường phức tạp với nhiều chướng ngại vật động hoặc tĩnh, tránh va chạm với thiết bị hoặc con người, hoặc di chuyển qua các không gian hạn chế một cách hiệu quả nhất, đặc biệt quan trọng đối với robot di động tự hành (AGV/AMR) trong các nhà máy và kho bãi.
Điều này mang lại lợi ích giảm thiểu thời gian di chuyển giữa các trạm làm việc, tiết kiệm năng lượng tiêu thụ của robot và các bộ truyền động của chúng, từ đó tăng năng suất tổng thể của hệ thống vận chuyển nội bộ và nâng cao hiệu quả logistics trong nhà máy thông qua việc quản lý luồng vật liệu tối ưu.

Tự động hóa các tác vụ khó lập trình là một thách thức lớn mà Robot học tăng cường có thể giải quyết hiệu quả, đặc biệt là những tác vụ đòi hỏi sự phán đoán, điều chỉnh liên tục dựa trên phản hồi của môi trường, hoặc kỹ năng tinh xảo của con người. Robot học cách thực hiện các tác vụ khó lập trình bằng tay hoặc đòi hỏi kỹ năng cao của con người, ví dụ như đánh bóng bề mặt với áp lực và quỹ đạo thay đổi liên tục theo hình dạng sản phẩm, hàn các đường nối phức tạp không đồng đều với khả năng thích ứng với các biến thể nhỏ, hoặc sơn các chi tiết có hình dạng độc đáo với chất lượng đồng đều.
Lợi ích là tăng độ chính xác và nâng cao chất lượng sản phẩm của các tác vụ này so với phương pháp thủ công, đồng thời giảm đáng kể chi phí nhân công và thời gian thiết lập ban đầu, cho phép doanh nghiệp tối ưu hóa nguồn lực và tăng cường khả năng cạnh tranh.
Robot cộng tác (Cobots) an toàn và hiệu quả hơn là một lĩnh vực ứng dụng đầy tiềm năng của Học tăng cường, tập trung vào sự tương tác an toàn và tự nhiên giữa con người và máy móc trong một không gian làm việc chung. Robot học cách tương tác an toàn và hiệu quả với con người trong môi trường làm việc chung, dự đoán ý định và hành động của con người thông qua dữ liệu từ thị giác máy và cảm biến lực, sau đó điều chỉnh hành vi của mình (ví dụ: giảm tốc độ, thay đổi quỹ đạo, hoặc dừng khẩn cấp) để tránh va chạm và đảm bảo an toàn lao động tối đa.
Điều này tăng cường khả năng hợp tác giữa người và robot, cho phép cobots làm việc hiệu quả hơn trong các tác vụ đòi hỏi sự hợp tác chặt chẽ (ví dụ: hỗ trợ người công nhân trong các tác vụ lắp ráp phức tạp), tối ưu hóa quy trình mà không làm gián đoạn dòng chảy công việc và tạo ra môi trường làm việc linh hoạt và an toàn hơn.
Tối ưu hóa quy trình sản xuất là một ứng dụng cấp cao và mang tính chiến lược, nơi Robot học tăng cường có thể đóng góp vào việc cải thiện hiệu suất toàn bộ dây chuyền sản xuất tự động và hệ thống. Robot học cách tối ưu hóa các thông số hoạt động của riêng mình và tương tác với các máy móc khác trong hệ thống Nhà máy thông minh.

Ví dụ, chúng có thể điều chỉnh tốc độ của dây chuyền sản xuất tự động để đạt hiệu suất cao nhất dựa trên tải trọng hiện tại, dự đoán và ngăn chặn các sự cố máy móc thông qua việc phân tích Big Data từ các cảm biến và bộ điều khiển robot, hoặc tối ưu hóa lịch trình sản xuất. Lợi ích là tăng năng suất tổng thể của nhà máy, giảm chi phí sản xuất do lãng phí hoặc thời gian ngừng hoạt động không mong muốn, và cải thiện hiệu quả vận hành, từ đó dẫn đến hiệu quả kinh tế cao hơn và lợi thế cạnh tranh bền vững trên thị trường.
Bảng 1: Các Ứng dụng chính của Robot học tăng cường trong sản xuất công nghiệp
| Lĩnh vực ứng dụng chính | Mô tả cụ thể chức năng của Robot học tăng cường | Lợi ích mang lại cho Sản xuất công nghiệp |
|---|---|---|
| Điều khiển linh hoạt | Robot học cách điều khiển khớp robot và end-effectors để thực hiện các tác vụ như gắp đặt vật thể không đồng nhất (bin picking), lắp ráp chi tiết có dung sai chặt, hoặc thao tác tinh vi. | Tăng cường linh hoạt và khả năng thích ứng của robot với môi trường không có cấu trúc hoặc thay đổi liên tục, giảm sự phụ thuộc vào sự sắp xếp vật liệu chính xác, tối ưu hóa quy trình sản xuất đa dạng. |
| Tối ưu hóa đường đi | Robot học cách tìm đường đi tối ưu và tránh chướng ngại vật động, tĩnh cho robot di động tự hành (AGV/AMR) trong môi trường nhà máy. | Giảm thời gian di chuyển, tiết kiệm năng lượng tiêu thụ của robot và bộ truyền động, tăng năng suất của hệ thống vận chuyển nội bộ và hiệu quả logistics. |
| Tự động hóa tác vụ khó lập trình | Robot học cách thực hiện các thao tác đòi hỏi kỹ năng cao của con người như đánh bóng bề mặt, hàn phức tạp, hoặc sơn mà không cần lập trình thủ công chi tiết. | Nâng cao độ chính xác và chất lượng sản phẩm, giảm đáng kể chi phí nhân công và thời gian thiết lập ban đầu, cho phép tự động hóa các quy trình trước đây chỉ có thể làm thủ công. |
| Robot cộng tác an toàn | Cobots học cách tương tác an toàn và hiệu quả với con người trong không gian làm việc chung, dự đoán hành động thông qua thị giác máy và cảm biến lực, điều chỉnh hành vi tránh va chạm. | Tăng cường an toàn lao động, cho phép cobots làm việc hiệu quả trong các tác vụ hợp tác giữa người và máy, tối ưu hóa quy trình làm việc và tạo môi trường linh hoạt. |
| Tối ưu hóa quy trình | Robot học cách điều chỉnh thông số hoạt động của dây chuyền sản xuất tự động, dự đoán và ngăn chặn sự cố máy móc, tối ưu hóa lịch trình và luồng sản xuất. | Tăng năng suất tổng thể của nhà máy, giảm chi phí sản xuất do lãng phí hoặc thời gian ngừng hoạt động, cải thiện hiệu quả vận hành và lợi nhuận, thúc đẩy Nhà máy thông minh. |
4. Tầm quan trọng của Robot học tăng cường trong sản xuất công nghiệp
Robot học tăng cường đã trở thành một yếu tố then chốt, mang lại những lợi ích chiến lược và thay đổi sâu sắc cách thức robot công nghiệp hoạt động trong môi trường sản xuất công nghiệp hiện đại, vượt xa các phương pháp tự động hóa truyền thống bằng cách trang bị cho chúng khả năng “tự học” và thích nghi, từ đó góp phần đáng kể vào sự phát triển của Nhà máy thông minh.
Giải quyết các bài toán điều khiển phức tạp là một trong những tầm quan trọng hàng đầu của Robot học tăng cường, bởi vì nó cung cấp khuôn khổ để robot giải quyết các bài toán mà các phương pháp lập trình truyền thống khó có thể xử lý hiệu quả. Điều này bao gồm các tác vụ trong môi trường không có cấu trúc (unstructured environments), nơi có sự bất định cao, hoặc các tác vụ đòi hỏi sự tương tác vật lý phức tạp (ví dụ: điều khiển lực, sự khéo léo trong thao tác).
Nhờ khả năng học hỏi thông qua thử và sai có hệ thống, thường được tăng tốc bởi các môi trường mô phỏng-thực (Sim-to-Real), robot có thể tìm ra các chiến lược tối ưu mà con người khó có thể mã hóa thủ công hoặc tốn kém rất nhiều thời gian và tài nguyên để lập trình chi tiết. Điều này mở rộng đáng kể phạm vi ứng dụng của robot trong các khía cạnh sản xuất phức tạp.
Tăng tính linh hoạt và khả năng thích ứng của Robot là một lợi ích quan trọng khác mà Học tăng cường mang lại, giúp robot thích ứng linh hoạt với các thay đổi trong môi trường làm việc mà không cần lập trình lại hoàn toàn. Điều này bao gồm sự xuất hiện đột ngột của chướng ngại vật mới, sự thay đổi vị trí của vật thể cần xử lý, hoặc biến đổi trong đặc tính vật liệu hoặc thông số sản phẩm.

Thay vì yêu cầu lập trình lại toàn bộ khi có sự thay đổi, robot có thể tự điều chỉnh hành vi của mình, duy trì hiệu suất hoạt động liên tục và ổn định trong các dây chuyền sản xuất tự động năng động và phức tạp, tối ưu hóa thời gian ngừng hoạt động và năng suất. Khả năng thích ứng này là tối quan trọng trong các kịch bản sản xuất lô nhỏ, tùy biến hàng loạt.
Giảm chi phí lập trình và bảo trì là một yếu tố kinh tế đáng kể khi áp dụng Robot học tăng cường vào sản xuất công nghiệp. Phương pháp này giảm thiểu đáng kể nhu cầu lập trình thủ công cho từng tác vụ hoặc từng biến thể của tác vụ, một quá trình tốn kém về thời gian, chi phí nhân công, và đòi hỏi kỹ năng chuyên môn cao về lập trình robot và bộ điều khiển robot.
Khi robot có khả năng tự học và tối ưu hóa hành vi của mình thông qua kinh nghiệm, chi phí liên quan đến việc thiết lập ban đầu và bảo trì hệ thống (bao gồm cả cập nhật phần mềm và điều chỉnh thông số hoạt động) cũng được giảm bớt, vì robot có thể tự thích nghi với các thay đổi nhỏ trong môi trường hoặc quy trình mà không cần can thiệp liên tục từ kỹ sư. Điều này cũng giúp ích cho chiến lược bảo trì dự đoán thông qua việc học các mẫu hành vi bất thường.
Mở ra các ứng dụng mới cho Robot là một tầm quan trọng chiến lược khác, khi Học tăng cường mở ra các ứng dụng hoàn toàn mới cho robot trong sản xuất công nghiệp mà trước đây là bất khả thi hoặc quá phức tạp để tự động hóa một cách hiệu quả. Điều này bao gồm khả năng tự động hóa các tác vụ khó lập trình bằng tay như đánh bóng bề mặt thủ công theo hình dạng phức tạp và không đồng đều, điều khiển robot trong môi trường nguy hiểm hoặc khắc nghiệt (ví dụ: môi trường phóng xạ, nhiệt độ cao) mà không cần sự hiện diện của con người, hoặc tối ưu hóa toàn bộ quy trình sản xuất một cách động dựa trên dữ liệu thời gian thực được thu thập từ IoT công nghiệp (IIoT) và Big Data.
Thúc đẩy sự phát triển của Nhà máy thông minh là mục tiêu cuối cùng mà Robot học tăng cường hướng tới, đặt nó là một trong những công nghệ cốt lõi và động lực chính cho sự phát triển của Nhà máy thông minh (Smart Factory) và kỷ nguyên Công nghiệp 4.0. Bằng cách trang bị cho các hệ thống robot khả năng học hỏi, thích nghi và tự tối ưu hóa liên tục, Học tăng cường giúp các nhà máy trở nên linh hoạt hơn, có khả năng phản ứng nhanh với các thay đổi trong nhu cầu thị trường (ví dụ: sản xuất cá nhân hóa, lô nhỏ), và đạt được mức độ tự động hóa thông minh cao hơn, từ đó tăng cường lợi thế cạnh tranh bền vững thông qua việc sử dụng hiệu quả Big Data, IoT công nghiệp (IIoT), và các bộ điều khiển robot thông minh tích hợp AI.
Danh sách: Tầm quan trọng chiến lược của Robot học tăng cường trong sản xuất công nghiệp
- Giải quyết các bài toán điều khiển phức tạp, vượt qua giới hạn lập trình truyền thống và mở rộng phạm vi tự động hóa.
- Tăng tính linh hoạt và khả năng thích ứng của Robot trước môi trường thay đổi và các yêu cầu sản xuất đa dạng.
- Giảm chi phí lập trình và bảo trì, tối ưu hóa nguồn lực và hiệu quả vận hành.
- Mở ra các ứng dụng mới đầy tiềm năng cho Robot, khai thác các lĩnh vực tự động hóa trước đây chưa khả thi.
- Thúc đẩy sự phát triển mạnh mẽ của Nhà máy thông minh và Công nghiệp 4.0, nâng cao năng lực cạnh tranh.

5. Các thách thức và xu hướng phát triển trong tương lai
Mặc dù Robot học tăng cường mang lại tiềm năng to lớn để cách mạng hóa robot công nghiệp, nhưng vẫn còn nhiều thách thức kỹ thuật và thực tiễn cần vượt qua trước khi nó có thể được triển khai rộng rãi. Song song đó, các xu hướng phát triển đang nổi lên hứa hẹn sẽ định hình tương lai của nó, biến robot trở nên thông minh và tự chủ hơn nữa trong các môi trường sản xuất phức tạp.
Khám phá và khai thác hiệu quả môi trường vẫn là một thách thức lớn đối với robot học tăng cường, đặc biệt trong thế giới thực nơi an toàn là tối quan trọng. Robot cần khám phá môi trường một cách hiệu quả để học được các chiến lược hành động tốt nhất mà không gây ra thiệt hại hoặc lãng phí quá nhiều thời gian và tài nguyên, đồng thời phải tránh các hành động nguy hiểm hoặc không an toàn trong quá trình học (ví dụ: va chạm với con người hoặc thiết bị đắt tiền).
Xu hướng phát triển trong lĩnh vực này tập trung vào việc phát triển các thuật toán khám phá hiệu quả hơn (ví dụ: khám phá dựa trên sự tò mò, khám phá có định hướng mục tiêu, học tập dựa trên mô hình), kết hợp Học tăng cường với các kỹ thuật khác như Học có giám sát và Học không giám sát để tận dụng dữ liệu sẵn có và giảm nhu cầu khám phá từ đầu, hoặc sử dụng các kỹ thuật định hình phần thưởng để hướng dẫn quá trình khám phá một cách an toàn hơn và có mục tiêu.
Chuyển giao kiến thức giữa các tác vụ và môi trường là một thách thức khác đối với Robot học tăng cường, bởi vì các mô hình robot học tăng cường thường rất cụ thể cho một tác vụ hoặc môi trường đã được huấn luyện. Điều này có nghĩa là robot thường phải học lại từ đầu cho mỗi tác vụ hoặc môi trường mới, điều này tốn kém về thời gian đào tạo và tài nguyên tính toán (đặc biệt khi triển khai nhiều robot hoặc nhiều tác vụ trong một dây chuyền sản xuất tự động).
Xu hướng phát triển đang hướng tới việc nghiên cứu các kỹ thuật Học chuyển giao (Transfer Learning) và Học đa nhiệm (Multi-task Learning). Học chuyển giao cho phép robot sử dụng kiến thức (mô hình, tham số, chiến lược) đã học được từ các tác vụ và môi trường tương tự trước đó để nhanh chóng thích nghi và học các tác vụ mới, giảm thời gian đào tạo và tăng hiệu quả triển khai. Học đa nhiệm cho phép robot học nhiều tác vụ cùng một lúc, chia sẻ các biểu diễn chung để cải thiện hiệu quả học tập và khả năng tổng quát hóa kiến thức.
Đảm bảo an toàn và độ tin cậy là yếu tố tối quan trọng và là một trong những rào cản lớn nhất đối với việc triển khai rộng rãi Robot học tăng cường, đặc biệt khi robot được triển khai trong môi trường sản xuất công nghiệp và làm việc cùng con người (như Robot cộng tác). Robot có thể thực hiện các hành động không mong muốn hoặc nguy hiểm trong quá trình học do khám phá ngẫu nhiên hoặc thiếu dữ liệu huấn luyện đầy đủ.
Xu hướng phát triển bao gồm việc phát triển các thuật toán Học tăng cường an toàn (safe RL), trong đó các hành động được giới hạn để không vượt quá các ngưỡng an toàn cho phép, hoặc kết hợp Học tăng cường với các kỹ thuật kiểm chứng và xác minh hình thức (formal verification) để đảm bảo hành vi của robot nằm trong giới hạn an toàn và tuân thủ các quy định an toàn lao động. Ngoài ra, Học giải thích được (Explainable AI – XAI) cũng là một xu hướng quan trọng để hiểu được lý do robot đưa ra quyết định, tăng cường sự tin cậy.
- Học từ dữ liệu ít ỏi là một rào cản thực tế khi triển khai Robot học tăng cường trong môi trường công nghiệp, vì các thuật toán này thường cần rất nhiều dữ liệu và tương tác (thường là hàng triệu lần thử và sai trong mô phỏng) để học được các chiến lược hành động tốt và ổn định. Việc thu thập dữ liệu trong thế giới thực có thể tốn kém, mất thời gian, và đôi khi nguy hiểm. Xu hướng phát triển đang tập trung vào các kỹ thuật Học ít mẫu (Few-shot Learning) và Học một lần (One-shot Learning), cho phép robot học từ dữ liệu ít ỏi bằng cách tận dụng kiến thức tiên nghiệm, mô hình nền tảng lớn (foundation models), hoặc khả năng suy luận từ các khái niệm cấp cao.
- Một kỹ thuật quan trọng khác là mô phỏng-thực (Sim-to-Real), cho phép robot học trong môi trường mô phỏng (ít tốn kém, an toàn) và sau đó chuyển giao kiến thức sang môi trường vật lý. Điều này sẽ giúp giảm đáng kể thời gian triển khai và làm cho Học tăng cường khả thi hơn trong các ứng dụng thực tế với nguồn dữ liệu hạn chế.
- Kết hợp Học tăng cường với các kỹ thuật khác là một xu hướng tổng hợp và mạnh mẽ, tạo ra các hệ thống robot thông minh và linh hoạt hơn bằng cách tận dụng điểm mạnh của nhiều phương pháp AI và công nghệ tiên tiến khác. Việc kết hợp Học tăng cường với Học sâu (Deep Learning) đã chứng minh được hiệu quả vượt trội (ví dụ như DQN, DDPG) trong việc xử lý dữ liệu phức tạp.
- Ngoài ra, sự tích hợp với thị giác máy (Machine Vision) cung cấp khả năng nhận thức thị giác tiên tiến để robot có thể “nhìn” và “hiểu” môi trường xung quanh, xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) có thể cho phép robot hiểu các lệnh phức tạp hơn từ con người và giao tiếp trực quan hơn. Sự phát triển của IoT công nghiệp (IIoT) cung cấp nguồn Big Data dồi dào từ các cảm biến và bộ điều khiển robot để huấn luyện các mô hình RL. Xu hướng này hướng tới việc tạo ra các hệ thống robot tự chủ, linh hoạt và có khả năng tương tác tự nhiên hơn với môi trường và con người, thúc đẩy sự phát triển của Robot cộng tác (Cobots) và toàn bộ Nhà máy thông minh một cách toàn diện. Đặc biệt, sự phát triển của Học sâu trên biên (Edge AI/Edge Computing) cho phép các mô hình RL chạy trực tiếp trên robot mà không cần kết nối liên tục với máy chủ đám mây, giảm độ trễ và tăng cường khả năng phản ứng.
Bảng 2: Các thách thức và xu hướng phát triển trong tương lai của Robot học tăng cường
| Thách thức chính | Xu hướng phát triển liên quan | Tác động tiềm năng đến Robot công nghiệp |
|---|---|---|
| Khám phá và khai thác hiệu quả môi trường | Phát triển thuật toán khám phá hiệu quả (cơ chế tò mò), kết hợp RL với SL/UL, định hình phần thưởng an toàn. | Tối ưu hóa quá trình học, giảm rủi ro va chạm trong giai đoạn đào tạo, tăng tốc độ triển khai robot trong các môi trường mới. |
| Chuyển giao kiến thức giữa các tác vụ/môi trường | Học chuyển giao (Transfer Learning), Học đa nhiệm (Multi-task Learning), mô hình nền tảng (foundation models). | Giảm đáng kể thời gian và chi phí đào tạo lại, robot nhanh chóng thích ứng với tác vụ/sản phẩm mới, tăng tính linh hoạt của dây chuyền sản xuất tự động. |
| Đảm bảo an toàn và độ tin cậy | Học tăng cường an toàn (Safe RL), kiểm chứng và xác minh hành vi, tích hợp giới hạn an toàn vào thuật toán. | Tăng cường an toàn lao động khi robot làm việc cạnh con người (Cobots), đảm bảo hành vi đáng tin cậy và tuân thủ quy định. |
| Học từ dữ liệu ít ỏi | Học ít mẫu (Few-shot Learning), Học một lần (One-shot Learning), học meta-learning, mô phỏng-thực (sim-to-real). | Khả thi triển khai RL trong các kịch bản dữ liệu hạn chế, giảm chi phí và thời gian thu thập dữ liệu thực tế, đẩy nhanh quá trình triển khai. |
| Kết hợp RL với các kỹ thuật AI khác | Tích hợp với Học sâu (Deep Learning), Thị giác máy (Machine Vision), Xử lý ngôn ngữ tự nhiên (NLP), IoT công nghiệp (IIoT). | Tạo ra robot thông minh, tự chủ, tương tác tự nhiên hơn với con người và môi trường, thúc đẩy sự phát triển toàn diện của Nhà máy thông minh. |

6. Kết luận
Tóm lại, Robot học tăng cường (Reinforcement Learning for robots) đại diện cho một bước tiến đột phá trong khả năng tự động hóa và thông minh hóa của robot công nghiệp, vượt xa những giới hạn của các hệ thống lập trình sẵn truyền thống. Bằng cách cho phép robot học hỏi thông qua tương tác trực tiếp với môi trường, nhận “phần thưởng” và “hình phạt”, RL trang bị cho chúng khả năng “tự học” và tối ưu hóa hành vi để đạt được các mục tiêu phức tạp trong thế giới thực mà không cần lập trình tường minh cho mọi kịch bản.
Việc tích hợp Robot học tăng cường không chỉ giải quyết các bài toán điều khiển phức tạp mà còn tăng cường đáng kể tính linh hoạt và khả năng thích ứng của robot trong các môi trường sản xuất đa dạng và thường xuyên thay đổi. Nó giảm thiểu chi phí lập trình và bảo trì nhờ khả năng tự học và thích nghi, đồng thời mở ra vô số ứng dụng mới cho robot trong sản xuất công nghiệp, từ gắp đặt linh hoạt các vật thể không định hình, lắp ráp phức tạp với độ chính xác cao, hàn chính xác các chi tiết phức tạp, cho đến việc tạo ra các Robot cộng tác (Cobots) an toàn và hiệu quả hơn khi làm việc cùng con người. Hơn nữa, Robot học tăng cường là một trong những công nghệ cốt lõi thúc đẩy sự phát triển của Nhà máy thông minh và kỷ nguyên Công nghiệp 4.0, nơi các hệ thống tự động có thể tự chủ, tối ưu hóa liên tục và phản ứng nhanh chóng với các biến động thị trường, tận dụng tối đa tiềm năng của Big Data và IoT công nghiệp (IIoT).
Mặc dù vẫn còn những thách thức về khám phá môi trường hiệu quả, chuyển giao kiến thức giữa các tác vụ, đảm bảo an toàn và học từ dữ liệu ít ỏi, các xu hướng phát triển mạnh mẽ như Học sâu trên biên (Edge Computing), các kỹ thuật mô phỏng-thực (Sim-to-Real), Học giải thích được (Explainable AI – XAI) và sự kết hợp với các công nghệ Trí tuệ nhân tạo khác hứa hẹn sẽ đưa Robot học tăng cường lên một tầm cao mới. Chúng tôi cam kết mang đến những giải pháp robot thông minh, có khả năng tự học và thích nghi, giúp doanh nghiệp bạn tối ưu hóa năng suất, nâng cao chất lượng sản phẩm, giảm chi phí vận hành và đảm bảo an toàn lao động, từ đó đạt được lợi thế cạnh tranh bền vững trong tương lai.