
Thị giác máy (Machine Vision)
Huấn Luyện Mô Hình và Tối Ưu Hóa CNN Chuyên Sâu Cho Machine Vision Công Nghiệp: Đạt Tốc Độ và Độ Chính Xác Tuyệt Đối

Quá trình Huấn luyện mô hình (Model Training) không chỉ là việc nạp dữ liệu vào thuật toán; đó là một nghệ thuật tối ưu hóa CNN để giải quyết các bài toán phức tạp trong sản xuất công nghiệp. Để đạt được độ chính xác gần 100% và tốc độ xử lý thời gian thực cần thiết cho Machine Vision, các doanh nghiệp phải làm chủ các kỹ thuật từ chuẩn bị dữ liệu chất lượng, áp dụng Transfer Learning hiệu quả, cho đến các chiến lược tinh giản mô hình để triển khai thành công trên thiết bị biên (Edge Devices).
1. Huấn luyện Mô hình – Chìa khóa chuyển đổi từ AI lý thuyết sang Sản xuất thực tế
Trong lĩnh vực Machine Vision của sản xuất công nghiệp, một mô hình học sâu (Deep Learning) chỉ là một tập hợp các thuật toán trừu tượng cho đến khi nó được truyền tải thông qua quá trình Huấn luyện mô hình.
Huấn luyện mô hình là quá trình tinh chỉnh các tham số (trọng số và độ lệch) của CNN dựa trên một lượng lớn dữ liệu hình ảnh đã được dán nhãn, để mô hình học cách đưa ra các dự đoán chính xác nhất quán. Tầm quan trọng trong Machine Vision Công nghiệp: Sự khác biệt lớn nhất giữa một mô hình hoạt động tốt trong phòng thí nghiệm và một mô hình hoạt động hiệu quả trên sàn nhà máy nằm ở quy trình tối ưu hóa CNN và huấn luyện thực chiến.
Trên dây chuyền sản xuất, mô hình không chỉ cần chính xác mà còn phải nhanh chóng, có khả năng tổng quát hóa tốt, và chịu đựng được các điều kiện hoạt động khắc nghiệt như biến đổi ánh sáng và góc nhìn.
Mục tiêu cuối cùng của quá trình này luôn là đạt được sự cân bằng tối ưu giữa hai yếu tố cốt lõi: Độ chính xác (Accuracy) (khả năng phát hiện đúng lỗi) và Tốc độ suy luận (Inference Speed) (tốc độ xử lý hình ảnh), điều này đặc biệt quan trọng cho các ứng dụng kiểm soát chất lượng tốc độ cao. Một mô hình có độ chính xác 99.9% nhưng mất 5 giây để xử lý là vô dụng trên băng chuyền sản xuất 100 sản phẩm/phút.

2. Chuẩn bị Dữ liệu: Nền tảng vàng cho sự thành công của CNN
Trong lĩnh vực học sâu, có một nguyên tắc vàng: Chất lượng dữ liệu quyết định 80% hiệu quả của Huấn luyện mô hình. Bất kỳ sự thiếu sót nào trong bước này sẽ dẫn đến mô hình hoạt động kém, không ổn định và không thể tổng quát hóa trong môi trường thực tế.
2.1. Thu thập Dữ liệu Công nghiệp: Thử thách và Giải pháp
Quá trình thu thập dữ liệu trong môi trường sản xuất công nghiệp là phức tạp hơn nhiều so với việc tải một tập dữ liệu công khai.
Thu thập: Điều quan trọng là phải thu thập đủ hình ảnh đại diện cho tất cả các điều kiện thực tế mà mô hình sẽ gặp. Điều này bao gồm các góc chụp khác nhau, ánh sáng thay đổi (cả mức chấp nhận được và mức có lỗi), các biến thể sản phẩm nhỏ, và quan trọng nhất là một lượng lớn mẫu Lỗi (cả lỗi tinh tế và lỗi rõ ràng).
Độ lệch Dữ liệu (Data Skew): Đây là một thử thách phổ biến: số lượng mẫu Đạt chuẩn thường vượt xa hàng nghìn lần so với số lượng mẫu Lỗi. Mô hình được Huấn luyện mô hình trên dữ liệu lệch sẽ thiên vị “Đạt chuẩn” và dễ dàng bỏ sót lỗi (False Negatives).
Giải pháp: Sử dụng kỹ thuật Oversampling (nhân bản mẫu lỗi) hoặc Undersampling (giảm mẫu đạt chuẩn), hoặc quan trọng hơn là tạo dữ liệu tổng hợp (Synthetic Data) để mô phỏng các loại lỗi hiếm gặp, giúp mô hình học hỏi hiệu quả hơn.
2.2. Dán nhãn Chính xác (Data Annotation/Labeling)
Dán nhãn là quá trình gán nhãn chính xác (ví dụ: “vết nứt”, “vị trí lắp vít”, “sản phẩm A”) cho từng hình ảnh hoặc từng khu vực trong hình ảnh.
Yêu cầu: Tùy thuộc vào bài toán Machine Vision Công nghiệp, ta chọn loại dán nhãn phù hợp:
- Classification (Phân loại): Gán một nhãn cho toàn bộ hình ảnh (“Hàng Đạt” hay “Hàng Lỗi”).
- Detection (Phát hiện): Khoanh vùng (Bounding Box) và dán nhãn cho vị trí của từng lỗi (ví dụ: lỗi A ở tọa độ x1,y1,x2,y2).
- Segmentation (Phân đoạn): Phân loại từng pixel thuộc về đối tượng hoặc lỗi (ví dụ: các pixel thuộc về vết trầy xước).
Tầm quan trọng của sự nhất quán: Lỗi dán nhãn (ví dụ: khoanh vùng sai vị trí lỗi, nhầm nhãn “vết nứt” thành “vết trầy”) sẽ trực tiếp gây nhầm lẫn cho Huấn luyện mô hình. Cần một bộ quy tắc dán nhãn nghiêm ngặt và công cụ chuyên dụng để đảm bảo tất cả kỹ sư dán nhãn tuân thủ một tiêu chuẩn đồng nhất.

2.3. Tăng cường Dữ liệu (Data Augmentation)
Tăng cường Dữ liệu là một kỹ thuật không thể thiếu để nâng cao chất lượng và số lượng tập dữ liệu mà không cần thu thập thêm hình ảnh vật lý.
- Chức năng: Tạo ra các biến thể mới của hình ảnh hiện có bằng cách áp dụng các phép biến đổi ngẫu nhiên như xoay, lật ngang/dọc, thay đổi độ sáng, thêm nhiễu (noise) hoặc làm mờ (blur).
- Mục đích: Tăng cường Dữ liệu giúp CNN học hỏi tốt hơn về các đặc trưng cơ bản (ví dụ: một vết nứt vẫn là vết nứt dù sản phẩm bị xoay 15 độ). Điều này tăng khả năng tổng quát hóa của mô hình và là biện pháp phòng ngừa chính yếu để giảm thiểu tình trạng học vẹt (Overfitting), đảm bảo mô hình hoạt động hiệu quả trên dữ liệu mới chưa từng thấy.
3. Quy trình Huấn luyện Mô hình CNN (Model Training) Chuyên sâu
Sau khi dữ liệu đã sẵn sàng, quá trình Huấn luyện mô hình bắt đầu, bao gồm việc lựa chọn kiến trúc, định nghĩa mục tiêu học tập và tinh chỉnh các tham số điều khiển.
3.1. Lựa chọn Kiến trúc và Cài đặt Tham số
- Kiến trúc: Việc chọn kiến trúc CNN phải dựa trên yêu cầu của bài toán Machine Vision Công nghiệp. Ví dụ, dùng ResNet cho bài toán phân loại sản phẩm tổng thể, dùng YOLO cho định vị đối tượng tốc độ cao, và dùng U-Net cho phát hiện lỗi bề mặt cần độ chính xác pixel.
- Hàm Mất Mát (Loss Function): Đây là “bộ chỉ huy” hướng dẫn mô hình học. Hàm mất mát đo lường sự khác biệt giữa dự đoán của mô hình và nhãn đúng. Tầm quan trọng của việc chọn đúng hàm mất mát là tối cao (ví dụ: dùng Cross-Entropy cho phân loại, dùng Mean Squared Error hoặc các phiên bản GIOU/DIOU cho định vị) để đảm bảo mô hình đi đúng hướng.
- Thuật toán Tối ưu (Optimizer): Các thuật toán như Adam, SGD (Stochastic Gradient Descent) đóng vai trò điều chỉnh trọng số của mô hình một cách hiệu quả nhất. Chúng xác định “bước nhảy” mà mô hình thực hiện trên không gian tham số để tìm đến điểm tối ưu (nơi hàm mất mát là nhỏ nhất). Adam thường được ưa chuộng vì tốc độ hội tụ nhanh hơn.
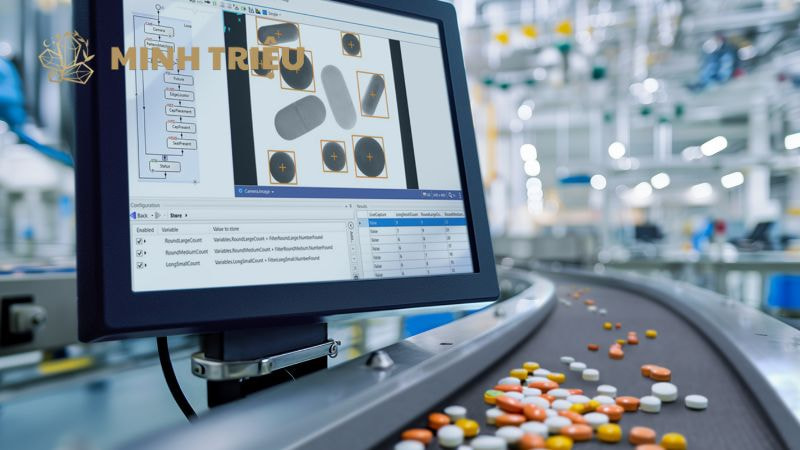
3.2. Kỹ thuật Transfer Learning (Học Chuyển Giao)
Transfer Learning là kỹ thuật không thể thiếu trong Machine Vision Công nghiệp vì nó giải quyết hai vấn đề lớn: thiếu dữ liệu và thiếu thời gian.
Khái niệm: Thay vì bắt đầu Huấn luyện mô hình từ các trọng số ngẫu nhiên, ta sử dụng các trọng số (Weights) đã được huấn luyện sẵn trên các tập dữ liệu cực lớn, có tính tổng quát hóa cao (ví dụ: ImageNet). Sau đó, ta tinh chỉnh lại (Fine-Tuning) các lớp cuối của mô hình trên tập dữ liệu công nghiệp nhỏ và chuyên biệt của mình.
Lợi ích:
- Tiết kiệm thời gian: Giảm đáng kể thời gian Huấn luyện mô hình, từ hàng tuần xuống còn vài giờ.
- Giảm nhu cầu dữ liệu: Vì mô hình đã học các đặc trưng cơ bản (cạnh, kết cấu, góc) từ trước, nó chỉ cần một lượng dữ liệu nhỏ hơn nhiều để học các đặc trưng cấp cao chuyên biệt của sản phẩm công nghiệp.
3.3. Huấn luyện thực tế và Quản lý Siêu tham số (Hyperparameter Tuning)
Các siêu tham số là các biến được thiết lập trước quá trình Huấn luyện mô hình và ảnh hưởng lớn đến hiệu suất.
Siêu tham số quan trọng:
- Tỷ lệ học (Learning Rate): Kiểm soát tốc độ mô hình học. Quá cao có thể làm mô hình không hội tụ; quá thấp làm thời gian huấn luyện kéo dài.
- Kích thước lô (Batch Size): Số lượng mẫu được xử lý trước khi trọng số được cập nhật. Kích thước lớn cần nhiều bộ nhớ GPU hơn nhưng có thể cho ra ước lượng gradient ổn định hơn.
- Số lượng epoch: Số lần toàn bộ tập dữ liệu được đưa qua mô hình. Cần được kiểm soát bởi kỹ thuật Early Stopping để tránh quá khớp.
Kỹ thuật Tinh chỉnh: Sử dụng các phương pháp như Grid Search (thử mọi tổ hợp tham số) hoặc Random Search (chọn ngẫu nhiên) để tìm ra bộ siêu tham số tối ưu cho bài toán cụ thể, giúp quá trình tối ưu hóa CNN đạt hiệu quả cao nhất.

4. Đánh giá và Cải thiện Hiệu năng Mô hình
Sau khi Huấn luyện mô hình hoàn tất, bước tiếp theo là đánh giá mô hình bằng các chỉ số khách quan để đảm bảo nó đạt chuẩn cho kiểm soát chất lượng công nghiệp.
4.1. Các Chỉ số Đánh giá Cốt lõi
Trong sản xuất công nghiệp, Độ chính xác (Accuracy) đơn thuần không đủ. Chúng ta cần các chỉ số nhạy cảm hơn đối với việc phát hiện lỗi bề mặt.
- Precision (Độ chính xác dương): Tỷ lệ các dự đoán “Lỗi” thực sự là lỗi. Chỉ số này quan trọng để Tránh cảnh báo giả (False Positives), vì cảnh báo giả làm tốn thời gian kiểm tra thủ công. Precision=TruePositives+FalsePositivesTruePositives
- Recall (Độ nhạy): Tỷ lệ các lỗi thực sự được mô hình phát hiện. Chỉ số này quan trọng để Tránh bỏ sót lỗi (False Negatives), vì bỏ sót lỗi là rủi ro chất lượng lớn nhất. Recall=TruePositives+FalseNegativesTruePositives
- F1-Score: Là trung bình điều hòa của Precision và Recall, dùng để đánh giá mô hình khi cần cân bằng cả hai yếu tố trên.
- Đường cong ROC và AUC: Đường cong ROC (Receiver Operating Characteristic) và diện tích dưới đường cong (AUC) cung cấp cái nhìn tổng quát về hiệu suất phân loại ở các ngưỡng quyết định khác nhau.
4.2. Xử lý các vấn đề Huấn luyện Thường gặp
- Quá khớp (Overfitting): Xảy ra khi mô hình học quá kỹ các chi tiết ngẫu nhiên và nhiễu trong dữ liệu huấn luyện, dẫn đến hiệu suất rất cao trên tập huấn luyện nhưng rất kém trên dữ liệu mới (Test Data).
- Giải pháp: Tăng cường dữ liệu, sử dụng kỹ thuật Dropout (vô hiệu hóa ngẫu nhiên một số nơ-ron trong quá trình huấn luyện), và sử dụng Early Stopping (dừng huấn luyện khi hiệu suất trên tập validation bắt đầu giảm).
- Dưới khớp (Underfitting): Xảy ra khi mô hình quá đơn giản hoặc chưa được huấn luyện đủ để học các đặc trưng cần thiết của dữ liệu.
- Giải pháp: Tăng độ sâu (Deep) của mô hình, tăng số lượng epoch, hoặc giảm các kỹ thuật Regularization quá mức.
5. Tối ưu hóa Mô hình cho Triển khai Thực tiễn (Deployment Optimization)
Đây là giai đoạn cuối cùng và quan trọng nhất để chuyển mô hình đã Huấn luyện mô hình thành một sản phẩm có thể triển khai trên dây chuyền sản xuất công nghiệp và chạy hiệu quả trên thiết bị biên.

5.1. Kỹ thuật Giảm kích thước Mô hình
Giảm kích thước mô hình là một chiến lược then chốt trong tối ưu hóa CNN để tăng tốc độ suy luận mà vẫn giữ được độ chính xác.
- Lượng tử hóa (Quantization): Kỹ thuật này giảm độ chính xác của các trọng số và phép toán (từ 32-bit Floating-point sang 8-bit Integer – Int8). Việc này giảm kích thước mô hình từ 4 lần và tăng tốc độ suy luận từ 2 đến 4 lần, do Int8 yêu cầu ít bộ nhớ và tài nguyên tính toán hơn. Đây là kỹ thuật then chốt trong tối ưu hóa CNN cho các hệ thống nhúng.
- Cắt tỉa (Pruning): Loại bỏ các kết nối và nơ-ron trong mạng có trọng số gần bằng không (ít quan trọng) để làm cho mô hình mỏng và nhẹ hơn. Sau khi cắt tỉa, mô hình sẽ cần được tinh chỉnh lại (Fine-Tuning) để khôi phục lại độ chính xác.
5.2. Triển khai trên Thiết bị Biên (Edge Computing)
Machine Vision Công nghiệp thường yêu cầu quyết định thời gian thực, làm cho việc triển khai trên Cloud (Đám mây) trở nên không khả thi do độ trễ mạng (Network Latency).
Lợi ích của Edge Computing: Giảm độ trễ (Latency) xuống mức mili giây, không cần phụ thuộc vào băng thông mạng, tăng tính riêng tư và bảo mật dữ liệu sản xuất.
Công cụ chuyên dụng:
- TensorRT (NVIDIA): Công cụ tối ưu hóa mô hình đã Huấn luyện mô hình để tận dụng tối đa kiến trúc GPU/Jetson của NVIDIA.
- OpenVINO (Intel): Bộ công cụ tối ưu hóa cho các bộ xử lý Intel, cho phép mô hình chạy hiệu quả trên các hệ thống tích hợp sẵn (embedded systems) hoặc Smart Camera.
Thử nghiệm Stress Test: Trước khi chính thức triển khai, mô hình cần được thử nghiệm căng thẳng trên phần cứng thực tế với khối lượng công việc cao nhất để đảm bảo hiệu năng và độ ổn định trong mọi điều kiện hoạt động của sản xuất công nghiệp.
6. Kết luận
Quy trình Huấn luyện mô hình và tối ưu hóa CNN là một chu trình liên tục, không bao giờ kết thúc; nó đòi hỏi sự kết hợp nhuần nhuyễn giữa kiến thức học sâu và hiểu biết sâu sắc về môi trường sản xuất công nghiệp. Việc làm chủ các kỹ thuật từ chuẩn bị dữ liệu, Transfer Learning cho đến Lượng tử hóa không chỉ giúp cải thiện độ chính xác và tốc độ kiểm soát chất lượng mà còn là yếu tố quyết định để duy trì lợi thế cạnh tranh, đẩy mạnh Machine Vision tiến gần hơn tới mục tiêu nhà máy không lỗi (Zero-Defect Manufacturing) trong kỷ nguyên tự động hóa.