
Thị giác máy (Machine Vision)
Mạng nơ-ron tích chập (CNN): Công Nghệ Cốt Lõi Cách Mạng Hóa Machine Vision Trong Sản Xuất Công Nghiệp

Mạng nơ-ron tích chập (CNN) là kiến trúc học sâu nền tảng, được thiết kế chuyên biệt để xử lý dữ liệu hình ảnh. Trong lĩnh vực Machine Vision của sản xuất công nghiệp, CNN đóng vai trò là bộ não, cho phép hệ thống tự động học hỏi các đặc trưng thị giác phức tạp, từ đó đạt được độ chính xác tuyệt đối trong việc phát hiện lỗi bề mặt, phân loại sản phẩm và định vị đối tượng mà các phương pháp truyền thống không thể thực hiện được.
1. Vai trò Cách mạng của CNN trong Machine Vision Hiện đại
Trong kỷ nguyên Công nghiệp 4.0, nhu cầu kiểm soát chất lượng (QC) và tự động hóa sản xuất công nghiệp đã vượt xa khả năng của con người và các hệ thống Machine Vision truyền thống. Trước đây, thị giác máy hoạt động dựa trên kỷ nguyên Rule-Based (dựa trên quy tắc), nơi các kỹ sư phải lập trình các quy tắc logic và thuật toán xử lý ảnh thủ công (như phát hiện cạnh, ngưỡng hóa) để đo lường các đặc trưng hình học đơn giản. M
ặc dù hiệu quả với các tác vụ cơ bản, phương pháp này nhanh chóng gặp bế tắc khi đối diện với sự phức tạp của thực tế. Sự xuất hiện của học sâu và cụ thể là Mạng nơ-ron tích chập (CNN) đã đánh dấu một bước ngoặt, chuyển Machine Vision sang kỷ nguyên tự động học hỏi từ dữ liệu.
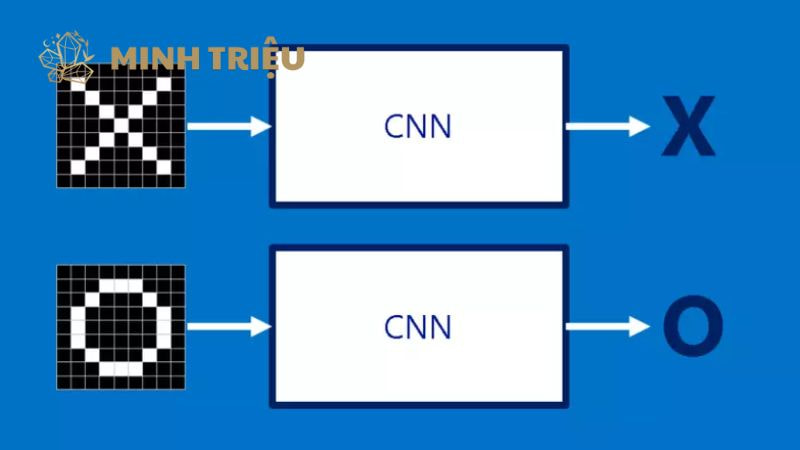
CNN là một loại mạng nơ-ron nhân tạo được thiết kế đặc biệt để xử lý dữ liệu đầu vào dạng lưới, chẳng hạn như hình ảnh. Cấu trúc độc đáo của nó cho phép nó trực tiếp tiếp nhận các pixel thô của hình ảnh và tự động học cách trích xuất các đặc trưng có ý nghĩa, loại bỏ hoàn toàn nhu cầu can thiệp thủ công. Trong sản xuất công nghiệp, các thách thức mà CNN giải quyết là vô cùng quan trọng, và vốn là tử huyệt của Machine Vision truyền thống:
- Lỗi ngẫu nhiên (Anomaly): Các lỗi mỹ phẩm, vết nứt tóc, hoặc các khuyết tật hiếm gặp, không thể định nghĩa bằng quy tắc lập trình.
- Bề mặt phức tạp: Vật liệu phản quang, bề mặt có kết cấu thô, hoặc các chi tiết đúc có hình dạng không đồng nhất.
- Biến đổi ánh sáng: Ngay cả trong môi trường kiểm soát, sự thay đổi nhỏ về ánh sáng cũng có thể phá vỡ các thuật toán dựa trên ngưỡng pixel cố định.
Mạng nơ-ron tích chập (CNN) vượt qua các rào cản này bằng khả năng học hỏi và tổng quát hóa, cho phép hệ thống duy trì độ chính xác cao ngay cả trong điều kiện thực tế khắc nghiệt nhất, từ đó trở thành trụ cột trung tâm của các giải pháp tự động hóa thông minh.
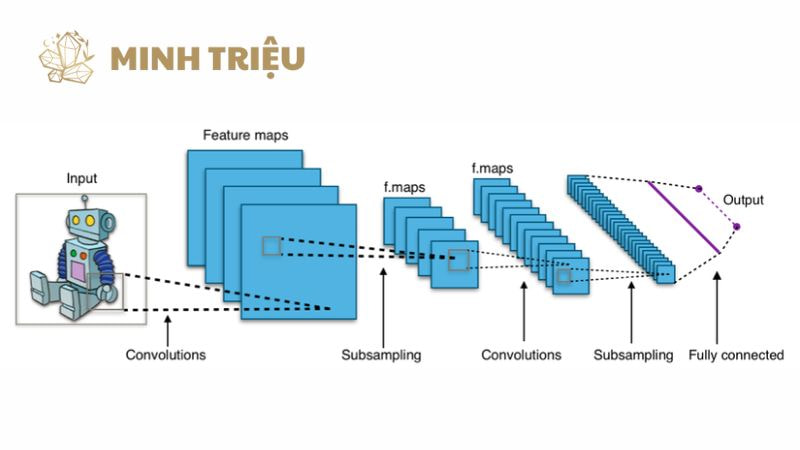
2. Cơ chế Hoạt động của Mạng nơ-ron tích chập (CNN)
Để hiểu tại sao Mạng nơ-ron tích chập (CNN) lại phù hợp cho Machine Vision, chúng ta cần phân tích cách nó xử lý thông tin hình ảnh theo một cơ chế hoàn toàn khác biệt so với các mạng nơ-ron truyền thống. CNN hoạt động bằng cách xây dựng một hệ thống cấp bậc để học hỏi và xử lý hình ảnh, bắt đầu từ các đặc điểm cơ bản nhất.
2.1. Lớp Tích chập (Convolutional Layer) – Phát hiện Đặc trưng
Đây là lớp cốt lõi, tạo nên sự khác biệt của CNN. Chức năng: Lớp Tích chập thực hiện một phép toán gọi là tích chập (convolution) trên dữ liệu đầu vào (hình ảnh). Quá trình này sử dụng một ma trận nhỏ gọi là Kernel hoặc Filter (bộ lọc). Bộ lọc này sẽ trượt (quét) qua toàn bộ hình ảnh, tại mỗi vị trí, nó thực hiện phép nhân từng cặp phần tử và cộng tổng để tạo ra một giá trị duy nhất trong ma trận đầu ra (Feature Map).
Vai trò của Kernel/Filter: Mỗi bộ lọc được huấn luyện để tìm kiếm một đặc điểm cơ bản cụ thể. Ví dụ, một bộ lọc có thể được tối ưu hóa để phát hiện các đường nét nằm ngang, một bộ lọc khác tìm kiếm các góc 45 độ, và một bộ lọc khác nhận dạng các đốm màu hoặc các thay đổi đột ngột về độ sáng.
Tính chất:
- Khả năng chia sẻ tham số (Parameter Sharing): Cùng một Kernel được áp dụng cho mọi vị trí pixel trên toàn bộ hình ảnh. Điều này giúp giảm đáng kể số lượng tham số cần học so với mạng nơ-ron truyền thống, khiến CNN hiệu quả hơn nhiều trong việc xử lý hình ảnh.
- Kết nối cục bộ (Local Connectivity): Mỗi nơ-ron trong lớp tích chập chỉ được kết nối với một vùng nhỏ của đầu vào (kích thước của Kernel). Điều này phản ánh cách mắt người hoạt động, chỉ xử lý thông tin tại một vùng cụ thể trước khi tổng hợp lại.
Kết quả của lớp tích chập là một tập hợp các Feature Map, mỗi Map biểu diễn nơi mà một đặc điểm cụ thể (ví dụ: một cạnh) được tìm thấy trong hình ảnh.
2.2. Lớp Gộp (Pooling Layer) – Giảm kích thước và Tăng tính Bất biến
Sau khi các đặc trưng được phát hiện bởi Lớp Tích chập, chúng thường đi qua Lớp Gộp. Chức năng: Lớp Gộp (thường là Max Pooling hoặc Average Pooling) thực hiện giảm kích thước không gian (Downsampling) của Feature Map. Ví dụ, Max Pooling sẽ chia Feature Map thành các ô 2×2 và chỉ giữ lại giá trị pixel lớn nhất trong mỗi ô.
Mục đích:
- Giảm tải tính toán: Giảm kích thước dữ liệu cần xử lý trong các lớp tiếp theo.
- Tăng tính Bất biến (Invariance): Giúp mô hình có tính bất biến đối với sự dịch chuyển nhỏ, xoay hoặc thay đổi tỷ lệ của vật thể. Nếu một đặc điểm (ví dụ: một góc) dịch chuyển một vài pixel, Max Pooling vẫn sẽ giữ lại đặc trưng đó. Điều này rất quan trọng trong sản xuất công nghiệp vì không phải lúc nào sản phẩm cũng nằm ở vị trí tuyệt đối chính xác.
2.3. Hệ thống Cấp bậc (Hierarchical Feature Learning)
Khả năng học đặc trưng theo cấp bậc là cốt lõi làm nên sức mạnh của học sâu và CNN.
Lớp nông (Shallow Layers): Các lớp tích chập ban đầu (gần với hình ảnh đầu vào) sẽ học các đặc trưng đơn giản và cơ bản nhất, chẳng hạn như các đường nét, kết cấu và sự thay đổi màu sắc thô.
Lớp sâu (Deep Layers): Khi tín hiệu đi qua các lớp tích chập sâu hơn, các lớp này sẽ học cách tổng hợp các đặc trưng đơn giản thành các biểu diễn trừu tượng và phức tạp hơn. Ví dụ, chúng có thể nhận dạng:
- Sự kết hợp của các cạnh tạo thành hình dạng chi tiết máy.
- Sự phân bố màu sắc đặc trưng của một vết nứt hoặc lỗi hở mạch.
- Mô hình lắp ráp của một cụm linh kiện.
Chính khả năng tự động trích xuất các đặc trưng trừu tượng, phức tạp này, mà không cần con người lập trình, đã cho phép CNN giải quyết các bài toán Machine Vision cao cấp.

2.4. Lớp Kết nối Toàn diện (Fully Connected Layer)
Sau khi CNN đã học và trích xuất thành công các đặc trưng cấp cao, các Feature Map cuối cùng sẽ được làm phẳng (Flatten) và đưa vào Lớp Kết nối Toàn diện.
Chức năng: Lớp này hoạt động như một bộ phân loại sản phẩm truyền thống. Nó sử dụng các đặc trưng đã học được để thực hiện tác vụ nhận dạng hoặc dự đoán cuối cùng. Ví dụ:
- Phân loại: Đưa ra xác suất sản phẩm là “Đạt” hay “Không đạt”.
- Định vị: Dự đoán tọa độ của Bounding Box.
Quá trình này hoàn tất vòng lặp: từ pixel thô, qua quá trình học đặc trưng sâu, đến kết quả dự đoán cuối cùng.
3. Các Kiến trúc CNN Nổi bật trong Machine Vision Công nghiệp
Thế giới của Mạng nơ-ron tích chập (CNN) rất đa dạng với nhiều kiến trúc được thiết kế cho các mục đích cụ thể, tối ưu hóa cho tốc độ và độ chính xác trong môi trường sản xuất công nghiệp.
3.1. Phân loại (Classification – VGG, ResNet)
Các kiến trúc này được tối ưu hóa cho việc phân loại sản phẩm (gán nhãn cho toàn bộ hình ảnh).
- VGG (Visual Geometry Group): Nổi tiếng với kiến trúc đơn giản, đồng nhất, sử dụng các Kernel 3×3 nhỏ. Mặc dù hiệu quả, VGG tương đối nặng.
- ResNet (Residual Network): Kiến trúc đột phá giải quyết vấn đề Gradient Vanishing bằng cách sử dụng Residual Blocks (Khối Dư). Khối này cho phép mô hình học các hàm nhận dạng (Identity Mapping) và có thể được xây dựng với độ sâu (Deep) rất lớn (ví dụ: ResNet-152), giúp học các đặc trưng phức tạp hơn mà không làm giảm hiệu suất huấn luyện.
- Ứng dụng: Chủ yếu dùng để phân loại sản phẩm theo SKU (Stock Keeping Unit), xác định loại vật liệu, hoặc phân biệt các lô hàng “Đạt” và “Không đạt” một cách tổng thể.

3.2. Phát hiện và Định vị Đối tượng (Object Detection – YOLO, Faster R-CNN)
Trong sản xuất công nghiệp, việc chỉ biết sản phẩm có lỗi hay không là chưa đủ; cần phải biết lỗi nằm ở đâu. Đây là vai trò của các mô hình Phát hiện Đối tượng.
- Faster R-CNN (Region-based Convolutional Neural Network): Thuật toán hai giai đoạn (Two-Stage Detector). Giai đoạn một xác định các vùng có khả năng chứa đối tượng (Region Proposals), sau đó giai đoạn hai sử dụng CNN để phân loại và tinh chỉnh vị trí các vùng đó. Rất chính xác nhưng chậm.
- YOLO (You Only Look Once): Thuật toán một giai đoạn (One-Stage Detector). YOLO xử lý toàn bộ hình ảnh chỉ trong một lần duy nhất. Nó chia hình ảnh thành lưới và dự đoán đồng thời cả Bounding Box (hộp bao quanh) và nhãn lớp (Class Label) cho từng ô lưới.
- Vai trò và Ứng dụng: Các mô hình này cực kỳ quan trọng trong Gắp đặt robot (Pick-and-Place), nơi hệ thống cần xác định vị trí, kích thước và hướng của nhiều linh kiện trên băng tải; hoặc trong kiểm tra lắp ráp, nơi cần xác định vị trí của từng ốc vít, chân cắm trên một bảng mạch.
3.3. Phân đoạn Ngữ nghĩa (Semantic Segmentation – U-Net)
Đây là cấp độ cao nhất của việc nhận dạng hình ảnh, nơi máy tính gán nhãn cho từng pixel trong hình ảnh.
- U-Net: Một kiến trúc được thiết kế như hình chữ U, bao gồm một đường đi giảm kích thước (Encoder – để học đặc trưng) và một đường đi tăng kích thước (Decoder – để phục hồi độ phân giải). U-Net sử dụng các kết nối bỏ qua (Skip Connections) giữa Encoder và Decoder để giữ lại thông tin chi tiết.
- Ứng dụng: Cực kỳ quan trọng trong Machine Vision công nghiệp để nhận dạng chính xác vùng lỗi bề mặt. Ví dụ, U-Net có thể phân tách từng pixel thuộc về “vết trầy xước”, “vùng keo dán thừa”, hoặc “vết nứt”, cho phép đo lường chính xác diện tích lỗi và hình dạng lỗi, một tác vụ bất khả thi với các phương pháp truyền thống.
4. Ứng dụng Thực tế của CNN trong Sản Xuất Công nghiệp
Mạng nơ-ron tích chập (CNN) đã trở thành công nghệ xương sống giải quyết hàng loạt các bài toán kiểm soát chất lượng cốt lõi trong sản xuất công nghiệp.

4.1. Kiểm tra Lỗi Bề mặt Phức tạp (Surface Defect Inspection)
Đây là ứng dụng nổi bật nhất, nơi CNN thể hiện sự khác biệt vượt trội.
- Sự khác biệt với truyền thống: Thuật toán truyền thống thường gặp lỗi giả (False Positives) hoặc bỏ sót lỗi (False Negatives) khi kiểm tra bề mặt có kết cấu phức tạp hoặc không đồng nhất (ví dụ: bề mặt kim loại đúc có vân, vải dệt, vật liệu nhựa có chứa hạt). CNN có thể học cách phân biệt giữa vân tự nhiên của vật liệu và khuyết tật thực sự.
- Giải pháp Anomaly Detection: Trong nhiều trường hợp, việc thu thập đủ mẫu lỗi là không thể. Các mô hình CNN dựa trên Anomaly Detection (Phát hiện Lỗi Ngẫu nhiên) chỉ được huấn luyện bằng hàng ngàn hình ảnh sản phẩm Đạt chuẩn. Bất kỳ sự khác biệt nào so với “Mẫu chuẩn” đều được báo cáo là khuyết tật. Phương pháp này đặc biệt hiệu quả trong việc phát hiện các lỗi chưa từng thấy trước đây (Novel Defects) trên màn hình, tấm wafer bán dẫn, hoặc các bề mặt đồng nhất khác.
4.2. Phân loại và Kiểm đếm Sản phẩm Đa dạng
CNN mang lại tính linh hoạt cao trong các tác vụ phân loại sản phẩm tốc độ cao.
- Phân loại sản phẩm linh hoạt: CNN có thể phân loại sản phẩm theo lô, SKU, hoặc theo chủng loại ngay cả khi chúng được sắp xếp ngẫu nhiên, bị xoay, nghiêng, hoặc chồng chéo một phần trên băng tải. Điều này loại bỏ nhu cầu về các thiết bị định hướng cơ học phức tạp.
- Đảm bảo chất lượng trong ngành thực phẩm: CNN được sử dụng rộng rãi để kiểm tra hình dạng, màu sắc và kết cấu của nông sản (ví dụ: phân loại táo bị dập, kiểm tra độ chín), hoặc kiểm tra sản phẩm chế biến (ví dụ: đảm bảo bánh quy có hình dạng hoàn hảo, không bị cháy, hoặc kiểm đếm số lượng miếng thịt trong khay).

4.3. Hướng dẫn Robot và Tự động hóa Lắp ráp
Khả năng định vị chính xác của CNN là chìa khóa cho robot thông minh.
- Bin Picking (Gắp các linh kiện lộn xộn): Đây là một bài toán phức tạp. Robot sử dụng hệ thống Machine Vision 3D kết hợp với các mô hình Phát hiện Đối tượng (YOLO) để nhận dạng và tính toán tọa độ X,Y,Z cùng với góc quay chính xác của từng linh kiện nằm lộn xộn trong thùng, sau đó cung cấp tọa độ này cho robot để gắp đặt.
- Kiểm tra Lắp ráp: CNN xác minh vị trí và sự hiện diện của hàng chục linh kiện trên một bảng mạch in (PCB) trong một lần chụp, đảm bảo các chân cắm, ốc vít, hoặc các module phụ đã được lắp đặt đúng vị trí và đúng hướng.
4.4. Đọc ký tự và Mã hóa (OCR/OCV)
Mặc dù có các thuật toán OCR truyền thống, CNN đã được tối ưu hóa để giải quyết các trường hợp khó khăn nhất trong việc đọc ký tự (Optical Character Recognition – OCR) và kiểm tra ký tự (Optical Character Verification – OCV).
- Thách thức: Đọc các ký tự bị biến dạng, in mờ, khắc laser mỏng trên các bề mặt phi phẳng (ví dụ: mã lot trên lốp xe, ngày sản xuất trên hộp giấy bị nhăn).
- Giải pháp: CNN học cách nhận dạng các mẫu ký tự ngay cả khi chúng bị thiếu thông tin hoặc có nhiễu nền cao, đạt được tỷ lệ đọc chính xác gần 100% trong các điều kiện ánh sáng và vật liệu không lý tưởng trong sản xuất công nghiệp.
5. Thách thức Triển khai và Tối ưu hóa Hiệu năng CNN
Việc áp dụng Mạng nơ-ron tích chập (CNN) vào Machine Vision không chỉ là về thuật toán mà còn là về kỹ thuật triển khai và tối ưu hóa hiệu năng trong môi trường sản xuất công nghiệp đòi hỏi tốc độ cao.
5.1. Tối ưu hóa Tốc độ Suy luận (Inference Speed)
Thách thức: Các mô hình CNN thường có hàng triệu tham số, dẫn đến yêu cầu tính toán lớn và dễ gây ra độ trễ (Latency) trong việc đưa ra quyết định. Trong một dây chuyền sản xuất xử lý hàng trăm sản phẩm mỗi phút, độ trễ chỉ 100ms cũng có thể dẫn đến thảm họa.
Giải pháp:
- Mô hình nhẹ (Lightweight Models): Sử dụng các kiến trúc được thiết kế để hiệu quả về tính toán như MobileNet, EfficientNet. Các mô hình này giảm số lượng tham số mà vẫn duy trì độ chính xác cao, rất phù hợp cho Machine Vision.
- Triển khai trên Thiết bị Biên (Edge Devices): Thay vì truyền dữ liệu hình ảnh về máy chủ trung tâm (Cloud), quá trình suy luận (Inference) được thực hiện trực tiếp trên thiết bị biên (Edge Devices) hoặc Smart Camera có tích hợp GPU/NPU (Neural Processing Unit). Điều này giảm độ trễ truyền dữ liệu xuống mức tối thiểu, cho phép đạt tốc độ mili giây cần thiết cho sản xuất công nghiệp.

5.2. Quản lý Dữ liệu và Dán nhãn (Data Labeling)
Thách thức: CNN cần một lượng lớn dữ liệu hình ảnh (Data Hungry) được dán nhãn chính xác (phân loại, khoanh vùng, phân đoạn). Quá trình dán nhãn thủ công là tốn kém, mất thời gian và dễ bị lỗi.
Giải pháp:
- Transfer Learning: Tận dụng các mô hình đã được huấn luyện sẵn trên các tập dữ liệu lớn để giảm đáng kể nhu cầu về dữ liệu huấn luyện mới.
- Công cụ Dán nhãn Bán tự động (Semi-Automated Labeling): Sử dụng các mô hình AI ban đầu để tự động dán nhãn dự đoán, sau đó con người chỉ cần kiểm tra và chỉnh sửa, làm tăng tốc độ và tính nhất quán của quá trình dán nhãn.
- Tăng cường Dữ liệu (Data Augmentation): Tạo ra dữ liệu giả (Synthetic Data) bằng cách áp dụng các biến đổi ngẫu nhiên (xoay, thay đổi độ sáng, thêm nhiễu) lên ảnh gốc để làm giàu tập dữ liệu.
5.3. Tính Giải thích của AI (Explainable AI – XAI)
- Thách thức: CNN là một “hộp đen”. Khi hệ thống đưa ra quyết định “Không đạt”, kỹ sư QC cần biết tại sao để truy nguyên nguyên nhân gốc rễ. Sự thiếu minh bạch làm giảm lòng tin vào hệ thống tự động.
- Giải pháp: Áp dụng các kỹ thuật XAI như CAM (Class Activation Maps). CAM giúp tạo ra một bản đồ nhiệt (Heatmap) trên hình ảnh, trực quan hóa và chỉ ra chính xác khu vực pixel nào mà mô hình CNN tập trung vào để đưa ra quyết định. Điều này không chỉ tăng tính minh bạch mà còn giúp kỹ sư xác định lỗi chính xác hơn, hỗ trợ quá trình cải tiến quy trình sản xuất công nghiệp.
6. Kết luận
Mạng nơ-ron tích chập (CNN) là công nghệ xương sống của Machine Vision thông minh, đã chuyển đổi quá trình kiểm soát chất lượng từ thủ công, dựa trên quy tắc, sang hệ thống tự động học và tự thích nghi. Khả năng tự động trích xuất đặc trưng của CNN giải quyết thành công các bài toán phức tạp nhất như phát hiện lỗi bề mặt ngẫu nhiên và định vị đối tượng chính xác trong môi trường sản xuất công nghiệp tốc độ cao. Sự kết hợp liên tục của CNN với Thị giác 3D và các mô hình tự giám sát (Self-supervised Learning) sẽ giúp các nhà máy đạt được cấp độ kiểm soát chất lượng hoàn toàn không có lỗi (Zero-Defect Manufacturing) trong tương lai.