
Trí tuệ nhân tạo trong tự động hóa
Tiền xử lý và Làm sạch Dữ liệu Công nghiệp: Yếu tố Quyết Định Cho AI trong Tự động hóa

Quy trình tiền xử lý và làm sạch dữ liệu công nghiệp không chỉ giúp loại bỏ sai lệch, nhiễu và dữ liệu ngoại lai mà còn đảm bảo tính toàn vẹn cho quá trình huấn luyện AI. Đây chính là bước nền tảng giúp hệ thống tự động hóa vận hành chính xác, đáng tin cậy và đạt hiệu suất tối ưu. Bài viết này phân tích các kỹ thuật tối ưu hóa quy trình tiền xử lý và làm sạch dữ liệu công nghiệp dựa trên kiến trúc Edge-Cloud, tập trung giải quyết các thách thức như dữ liệu không đồng nhất và ngoại lai trong mạng công nghiệp.
1. Giới thiệu Cầu nối giữa Dữ liệu Thô IIoT và AI Thành công
Trí tuệ nhân tạo trong tự động hóa (AI in Automation) cần Chất lượng dữ liệu hoàn hảo để đảm bảo tính chính xác và Độ tin cậy cao của các quyết định đưa ra trong môi trường sản xuất. Chất lượng dữ liệu giữ vai trò thiết yếu, bởi vì mọi mô hình Học máy (Machine Learning) hay Học sâu (Deep Learning) đều chỉ có thể tối ưu hóa hiệu suất dựa trên tính toàn vẹn của tập dữ liệu đã được Huấn luyện mô hình.
Dữ liệu lớn thô thu thập từ Cảm biến thông minh và Hệ sinh thái IIoT luôn bao gồm nhiều sai sót cố hữu như nhiễu, giá trị ngoại lai, hoặc thiếu hụt do sự phức tạp của Mạng công nghiệp và môi trường vật lý khắc nghiệt. Tiền xử lý và làm sạch dữ liệu công nghiệp chính là cầu nối chuyển đổi luồng thông tin hỗn tạp này thành tập dữ liệu có cấu trúc, cho phép các thuật toán AI hoạt động hiệu quả trong các ứng dụng Điều khiển thời gian thực và Bảo trì dự đoán.
Công nghệ Tiền xử lý và làm sạch dữ liệu công nghiệp được xem là bước bắt buộc để giải quyết những thách thức cố hữu của việc thu thập thông tin từ các thiết bị IoT/OT đa dạng. Sự chuyển đổi từ Sản xuất truyền thống sang Nhà máy thông minh đã làm tăng đáng kể khối lượng Dữ liệu lớn và tính không đồng nhất của chúng, đòi hỏi các quy trình xử lý dữ liệu phức tạp hơn so với trước đây.

Bằng cách thực hiện các bước làm sạch như loại bỏ nhiễu và điền khuyết, cùng với các bước tiền xử lý như chuẩn hóa và trích xuất đặc trưng, doanh nghiệp có thể đảm bảo rằng các mô hình AI được Huấn luyện mô hình sẽ đưa ra các dự đoán chính xác và nhất quán, góp phần đạt được Tính xác định trong quy trình tự động hóa.
Nếu bỏ qua giai đoạn quan trọng này, dù mô hình AI có tinh vi đến đâu cũng sẽ gặp phải hiện tượng “garbage in, garbage out,” dẫn đến các quyết định tự động hóa sai lầm, gây thiệt hại nghiêm trọng.
2. Thách thức của Dữ liệu Lớn Công nghiệp (Industrial Big Data)
2.1. Nguồn gốc dữ liệu và Tính không đồng nhất
Dữ liệu lớn công nghiệp phát sinh từ vô số nguồn IoT/OT khác nhau, gây ra thách thức lớn về Tính không đồng nhất trong cấu trúc và định dạng. Các nguồn này bao gồm Cảm biến thông minh đo các thông số vật lý (nhiệt độ, độ rung, áp suất), Bộ điều khiển logic khả trình (PLC), hệ thống Thực thi Sản xuất (MES), và hệ thống Hoạch định Tài nguyên Doanh nghiệp (ERP). Mỗi loại thiết bị này thường sử dụng các giao thức truyền thông và tốc độ ghi dữ liệu khác nhau—ví dụ, MQTT cho Thiết bị Biên nhẹ và OPC UA cho tích hợp hệ thống cấp cao.
Sự đa dạng này buộc phải có các giải pháp Tiền xử lý và làm sạch dữ liệu công nghiệp phức tạp để hợp nhất các luồng dữ liệu riêng lẻ này thành một tập hợp thống nhất có thể dùng cho Huấn luyện mô hình Học sâu. Sự khác biệt về tốc độ lấy mẫu (sampling rate) giữa các Cảm biến thông minh tạo ra sự phức tạp cố hữu trong việc Đồng bộ hóa dữ liệu thời gian (Time Series Synchronization).
Một cảm biến độ rung phục vụ Bảo trì dự đoán có thể ghi nhận dữ liệu với tần số hàng kilohertz, trong khi một cảm biến nhiệt độ đơn giản có thể chỉ ghi lại mỗi phút một lần. Khi kết hợp các thông số này để tạo ra một hồ sơ hoạt động toàn diện cho mô hình AI, việc căn chỉnh dấu thời gian bị sai lệch (time drift) trở thành một bước tiền xử lý khó khăn.
Nếu dữ liệu không được đồng bộ hóa chính xác, mô hình AI sẽ nhận định sai mối quan hệ nhân quả giữa các biến số, làm giảm mạnh khả năng dự đoán và Điều khiển thời gian thực.
2.2. Các vấn đề cốt lõi của Dữ liệu thô
Dữ liệu thô từ Mạng công nghiệp thường xuyên chứa đựng ba vấn đề cốt lõi: dữ liệu ngoại lai, dữ liệu thiếu, và dữ liệu nhiễu, làm suy giảm nghiêm trọng Độ tin cậy cao của hệ thống AI. Dữ liệu ngoại lai (Outliers) bao gồm các giá trị ghi nhận bất thường, có thể là do sự cố vật lý đột ngột, lỗi cảm biến tức thời, hoặc nhiễu điện từ quá mức.
Dữ liệu thiếu (Missing Data) thường xuất hiện dưới dạng giá trị Null hoặc NaN, nguyên nhân chính là mất kết nối trong Hệ sinh thái IIoT do Băng thông không ổn định hoặc sự cố mạng 5G/Wi-Fi tạm thời. Cuối cùng, Dữ liệu nhiễu (Noise) là các biến động ngẫu nhiên, không mong muốn trong tín hiệu, luôn hiện diện trong mọi môi trường Sản xuất truyền thống và hiện đại, làm che mờ thông tin thực tế mà AI cần học hỏi.
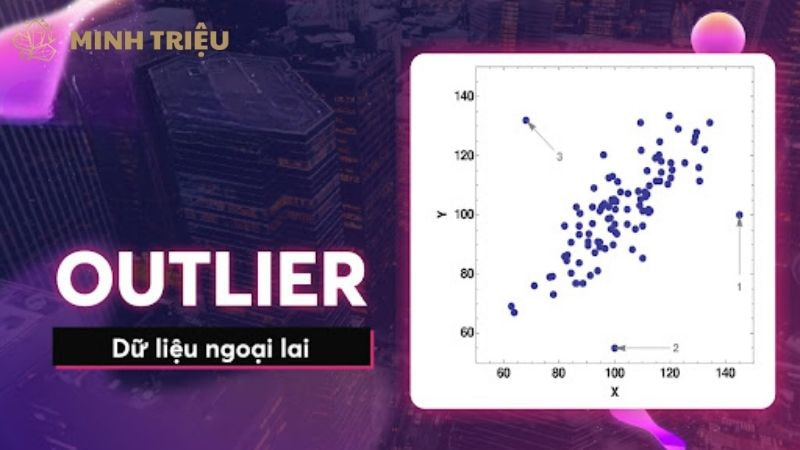
Việc không xử lý kịp thời Dữ liệu nhiễu và ngoại lai có thể dẫn đến việc Huấn luyện mô hình AI thất bại hoặc tạo ra các quyết định Điều khiển thời gian thực không chính xác. Nếu mô hình Học sâu được huấn luyện trên dữ liệu nhiễu, nó sẽ không thể khái quát hóa (generalize) tốt, dẫn đến kết quả Inference (suy luận) kém chính xác trong môi trường sản xuất thực tế.
Đối với các ứng dụng Điều khiển thời gian thực, một giá trị ngoại lai không được làm sạch có thể kích hoạt cơ chế dừng máy khẩn cấp (false positive) hoặc ngược lại, bỏ qua một lỗi thực sự (false negative), gây ảnh hưởng trực tiếp đến hiệu suất và an toàn của Nhà máy thông minh.
3. Làm sạch Dữ liệu (Data Cleaning): Loại bỏ khiếm khuyết
3.1. Xử lý Dữ liệu thiếu và lỗi
Xử lý Dữ liệu thiếu và lỗi là bước đầu tiên trong Tiền xử lý và làm sạch dữ liệu công nghiệp, nhằm khôi phục Tính toàn vẹn (Integrity) của tập dữ liệu. Các giá trị thiếu, thường được mã hóa là NaN (Not a Number), cần phải được nhận diện và xử lý. Nếu số lượng dữ liệu thiếu quá ít, phương pháp đơn giản nhất là loại bỏ các hàng (samples) chứa giá trị NaN.
Tuy nhiên, trong Dữ liệu lớn chuỗi thời gian công nghiệp, việc loại bỏ dữ liệu có thể làm mất thông tin quan trọng về các sự kiện liên tục. Các kỹ thuật điền khuyết (Imputation) tiên tiến được sử dụng để dự đoán các giá trị thiếu dựa trên dữ liệu lân cận, thay vì chỉ dựa vào thống kê đơn thuần.
- Điền khuyết Thống kê: Sử dụng giá trị trung bình (Mean) hoặc trung vị (Median) của toàn bộ thuộc tính hoặc của cửa sổ thời gian gần nhất.
- Điền khuyết Nội suy (Interpolation): Phương pháp này được ưa chuộng hơn cho dữ liệu chuỗi thời gian, sử dụng thuật toán nội suy tuyến tính (Linear Interpolation) hoặc nội suy theo đường cong (Spline Interpolation) để ước tính giá trị tại điểm thiếu, đảm bảo tính liên tục của dữ liệu.
- Lọc Nhiễu: Để giảm thiểu ảnh hưởng của Dữ liệu nhiễu, các bộ lọc kỹ thuật số (như Bộ lọc Kalman hoặc Bộ lọc Thông thấp/Thông cao) được áp dụng. Việc này giúp tách biệt tín hiệu cần thiết cho Huấn luyện mô hình AI khỏi tạp âm ngẫu nhiên.
3.2. Phát hiện và xử lý Dữ liệu ngoại lai
Dữ liệu ngoại lai cần được phát hiện và xử lý cẩn thận, bởi vì chúng có thể làm sai lệch nghiêm trọng các tham số Huấn luyện mô hình Học sâu. Nếu không được kiểm soát, một vài điểm ngoại lai có thể khiến mô hình AI tập trung quá mức vào việc giải thích các điểm dữ liệu không điển hình này, làm giảm khả năng khái quát hóa. Các phương pháp phát hiện dựa trên thống kê thường được sử dụng làm cơ sở để xác định ngưỡng cảnh báo đối với Dữ liệu ngoại lai.
- Phạm vi Liên Phân vị (IQR – Interquartile Range): Phương pháp này hiệu quả vì nó ít nhạy cảm với chính các giá trị ngoại lai so với độ lệch chuẩn. Một điểm dữ liệu được coi là ngoại lai nếu nó nằm ngoài phạm vi Q1−1.5×IQR và Q3+1.5×IQR.
- Phân tích Z-score: Sử dụng độ lệch chuẩn để xác định các điểm dữ liệu nằm cách xa giá trị trung bình một số lượng độ lệch chuẩn nhất định (thường là >3).
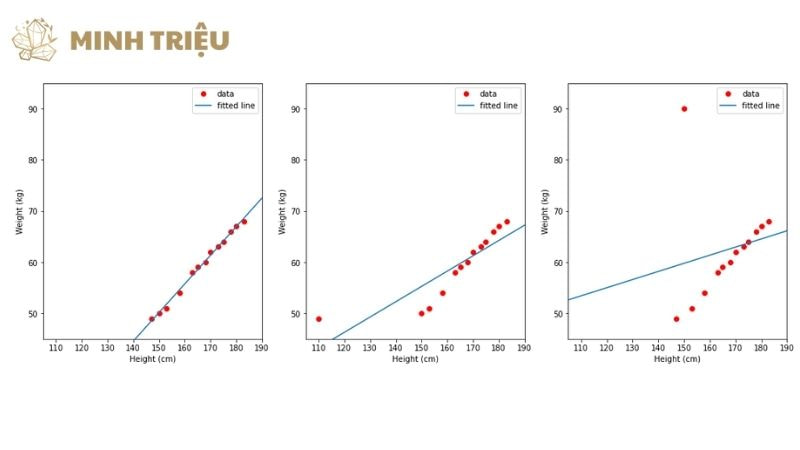
Đối với dữ liệu lớn phức tạp, mô hình Học máy được sử dụng để nhận dạng các bất thường tinh vi hơn, đặc biệt quan trọng cho Bảo trì dự đoán. Các thuật toán như Isolation Forest hoặc Local Outlier Factor (LOF) có thể xác định các điểm ngoại lai không tuân theo mô hình phân bố đa chiều của dữ liệu, giúp cải thiện Độ tin cậy cao của việc phát hiện bất thường trong Hệ sinh thái IIoT.
4. Tiền xử lý Dữ liệu (Data Preprocessing): Chuẩn bị cho Huấn luyện Mô hình
4.1. Chuẩn hóa và Quy mô hóa Dữ liệu (Normalization and Scaling)
Chuẩn hóa và Quy mô hóa dữ liệu là bước tiền xử lý quan trọng, đảm bảo tất cả các thuộc tính Dữ liệu lớn có cùng trọng số tương đối trong quá trình huấn luyện mô hình Học sâu. Trong sản xuất, các thông số vật lý có phạm vi giá trị cực kỳ khác nhau.
Ví dụ: nhiệt độ có thể là 50∘C trong khi độ rung có thể là 0.05 mm/s. Nếu mô hình AI xử lý trực tiếp các giá trị này, nó sẽ thiên vị các thuộc tính có giá trị lớn hơn (như nhiệt độ), làm giảm khả năng học hỏi từ các tín hiệu quan trọng nhưng nhỏ hơn (như độ rung) đối với Bảo trì dự đoán. Việc lựa chọn giữa Chuẩn hóa Min-Max và Quy mô hóa Z-score (Standardization) phụ thuộc vào phân phối thống kê của tập dữ liệu.
- Chuẩn hóa Min-Max: Chuyển đổi dữ liệu về phạm vi [0,1], phù hợp cho các thuật toán yêu cầu giá trị đầu vào nằm trong giới hạn cố định (ví dụ: một số mạng nơ-ron). Công thức: Xnorm=Xmax−XminX−Xmin
- Quy mô hóa Z-score (Standardization): Chuyển đổi dữ liệu sao cho có giá trị trung bình là 0 và độ lệch chuẩn là 1, thường được ưu tiên khi dữ liệu tuân theo phân phối chuẩn (Gaussian distribution). Công thức: Xstd=σX−μ
Quy mô hóa Z-score đặc biệt mạnh mẽ vì nó làm giảm ảnh hưởng của các giá trị ngoại lai so với Chuẩn hóa Min-Max, giúp tăng cường Tính xác định của mô hình AI.
4.2. Đồng bộ hóa Dữ liệu Thời gian (Time Series Synchronization)
Đồng bộ hóa Dữ liệu Thời gian là yêu cầu tối quan trọng đối với các ứng dụng Điều khiển thời gian thực và Phân tích dữ liệu thời gian thực trong Hệ sinh thái IIoT. Vì các Cảm biến thông minh và Thiết bị Biên hoạt động độc lập với tốc độ xung nhịp khác nhau, việc căn chỉnh các dấu thời gian để tạo thành một chuỗi sự kiện duy nhất là bắt buộc.
Sai lệch thời gian (time drift) dù nhỏ cũng có thể làm mô hình AI kết luận sai về mối quan hệ giữa các biến số, ví dụ, cho rằng sự tăng áp suất xảy ra sau khi nhiệt độ giảm, thay vì ngược lại. Để đạt được sự Đồng bộ hóa dữ liệu thời gian hoàn hảo, các kỹ thuật sau đây cần được áp dụng:
- Căn chỉnh Mốc thời gian (Timestamp Alignment): Đảm bảo tất cả dữ liệu được chuyển đổi sang cùng một mốc thời gian chung và xử lý các độ lệch micro giây.
- Tái lấy mẫu (Resampling): Dữ liệu phải được tái lấy mẫu về cùng một tần số cố định (ví dụ: mỗi 100ms) để các tập dữ liệu có thể được kết hợp theo chiều ngang. Đối với dữ liệu thô, các phương pháp Nội suy được sử dụng để tạo ra các điểm dữ liệu bị thiếu trong quá trình tái lấy mẫu. Các giao thức Mạng công nghiệp như TSN (Time-Sensitive Networking) đóng vai trò nền tảng, đảm bảo Độ trễ cực thấp và Tính xác định trong truyền tải, từ đó giảm thiểu sự cần thiết của việc bù trừ thời gian quá mức ở lớp Cloud Computing.

4.3. Kỹ thuật trích xuất Đặc trưng (Feature Engineering)
Kỹ thuật trích xuất Đặc trưng là quá trình sáng tạo ra các thuộc tính mới, mang ý nghĩa vật lý rõ ràng hơn từ Dữ liệu lớn thô, nhằm tăng cường khả năng Huấn luyện mô hình AI. Các mô hình AI thường hoạt động hiệu quả hơn khi được cung cấp các đặc trưng đã được tính toán sẵn thay vì dữ liệu thô.
Trong Sản xuất truyền thống, các đặc trưng này thường được tạo ra thủ công; trong Nhà máy thông minh, chúng được tự động hóa. Ví dụ điển hình nhất về Trích xuất Đặc trưng trong AI công nghiệp là Phân tích phổ tần số (FFT) cho Bảo trì dự đoán:
- Tín hiệu thô: Dạng sóng độ rung theo thời gian từ Cảm biến thông minh. Dữ liệu này rất lớn và khó để mô hình Học sâu phân tích trực tiếp.
- Trích xuất Đặc trưng: Áp dụng biến đổi Fourier nhanh (FFT) để chuyển đổi dạng sóng này sang miền tần số. Các đặc trưng mới được tạo ra bao gồm: Tần số đỉnh, Biên độ đỉnh, và các chỉ số thống kê (ví dụ: Kurtosis, Skewness). Các đặc trưng tần số này có mối liên hệ trực tiếp với các lỗi máy móc cụ thể (ví dụ: tần số 1×,2× tốc độ quay), giúp mô hình AI dự đoán lỗi ổ trục hoặc bánh răng chính xác hơn nhiều. Quá trình trích xuất đặc trưng này thường được thực hiện ngay tại Thiết bị Biên thông qua Edge AI để giảm Băng thông truyền tải lên Cloud Computing.
5. Tối ưu hóa Tiền xử lý bằng Edge Computing
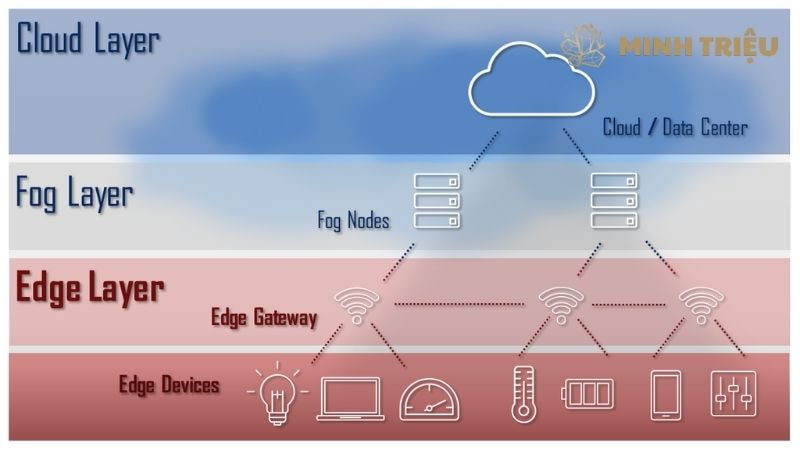
5.1. Chuyển đổi Tiền xử lý lên Thiết bị Biên (Edge Layer)
Chuyển đổi quy trình Tiền xử lý và làm sạch dữ liệu công nghiệp lên Thiết bị Biên (Edge Layer) là giải pháp kiến trúc để đối phó với thách thức Độ trễ và Băng thông lớn của Dữ liệu lớn IIoT. Trong kiến trúc truyền thống, Dữ liệu lớn thô được gửi trực tiếp lên Cloud Computing để xử lý, tạo ra Độ trễ không thể chấp nhận được cho các ứng dụng Điều khiển thời gian thực.
Tính toán Biên (Edge Computing) giải quyết vấn đề này bằng cách đặt năng lực tính toán gần nguồn dữ liệu, tức là gần Cảm biến thông minh. Việc thực hiện Tiền xử lý tại Edge giúp giảm đáng kể nhu cầu Băng thông mạng, đồng thời tăng tốc độ phản hồi cho AI trong Tự động hóa. Thay vì gửi hàng gigabyte dữ liệu rung động thô hoặc video 4K lên đám mây, Thiết bị Biên thực hiện việc lọc nhiễu, điền khuyết, và quan trọng nhất là trích xuất đặc trưng (FFT) ngay tại chỗ.
Kết quả là chỉ các gói dữ liệu nhỏ, đã được làm sạch và nén, hoặc chỉ các sự kiện cảnh báo (Exception Reporting) được truyền qua Mạng công nghiệp bằng giao thức MQTT hoặc 5G, tối ưu hóa việc sử dụng Băng thông và giảm chi phí truyền tải.
5.2. Edge AI và Tiền xử lý thông minh
Edge AI tích hợp khả năng Học máy/Học sâu đơn giản vào Thiết bị Biên, cho phép các thao tác Tiền xử lý thông minh, cục bộ, và tự động. Thay vì chỉ là một công cụ xử lý thụ động, Cảm biến thông minh hiện đại có thể được coi là các Thiết bị Biên thông minh có khả năng chạy các mô hình Học sâu đã được Nén mô hình (Model Compression). Khả năng Edge AI nâng cao Tính xác định và Độ tin cậy cao của các quyết định Điều khiển thời gian thực.
- Phát hiện Ngoại lai Cục bộ: Một mô hình Edge AI nhỏ có thể liên tục theo dõi dữ liệu đầu vào và tự động loại bỏ các điểm ngoại lai ngay tại cảm biến trước khi truyền đi, đảm bảo tính chính xác của dữ liệu được gửi đến hệ thống Cloud Computing để Huấn luyện mô hình phức tạp hơn.
- Xác định Ngưỡng động: Edge AI không chỉ dựa vào các ngưỡng cố định mà có thể sử dụng các mô hình nhỏ để dự đoán sự thay đổi bình thường của tham số theo điều kiện vận hành, từ đó đưa ra cảnh báo chính xác hơn về lỗi máy móc trong Bảo trì dự đoán. Sự phân tán trí tuệ này, nơi AI thực hiện Inference tức thời tại Thiết bị Biên, là chìa khóa để đạt được Độ trễ cực thấp cần thiết cho các hệ thống an toàn và điều khiển khẩn cấp trong Nhà máy thông minh.
6. Kết luận
Tiền xử lý và làm sạch dữ liệu công nghiệp là bước nền tảng quyết định sự thành công và tính toàn vẹn của mọi dự án AI trong tự động hóa. Toàn bộ quy trình, từ thu thập dữ liệu thô qua cảm biến và IIoT đến ra quyết định thời gian thực, đều phụ thuộc vào chất lượng dữ liệu đã xử lý. Các bước như làm sạch (loại nhiễu, xử lý ngoại lai, điền khuyết) và tiền xử lý (chuẩn hóa, đồng bộ thời gian, trích xuất đặc trưng) giúp biến dữ liệu thô thành thông tin có giá trị. Kiến trúc Edge-Cloud tối ưu quy trình này nhờ khả năng tính toán biên, cho phép xử lý dữ liệu ngay tại thiết bị, giảm độ trễ, tiết kiệm băng thông và nâng cao độ tin cậy cho các ứng dụng quan trọng như bảo trì dự đoán và thị giác máy trong nhà máy thông minh.