
Thị giác máy (Machine Vision)
Phát hiện đối tượng với YOLO và Faster R-CNN: Phân tích chuyên sâu và chiến lược tối ưu hóa trong Machine Vision Công nghiệp
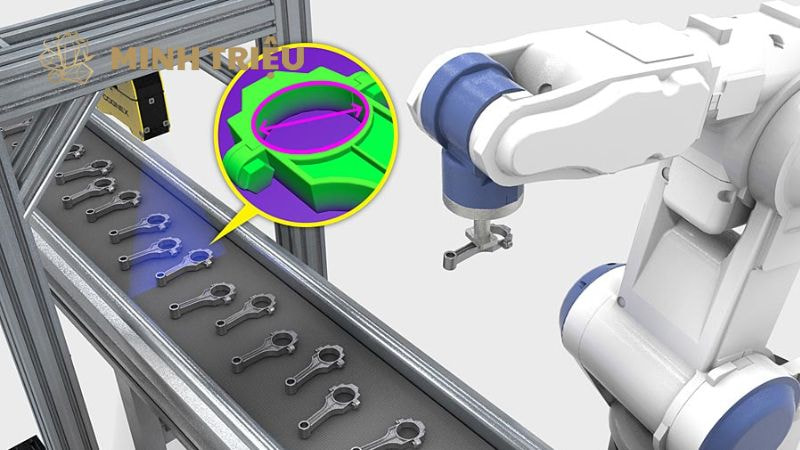
Phát hiện đối tượng (Object Detection) là công nghệ cốt lõi giúp Machine Vision vượt qua giới hạn phân loại đơn thuần, cho phép hệ thống không chỉ nhận biết có lỗi hay không lỗi, mà còn xác định vị trí chính xác của lỗi, bộ phận. Trong sản xuất công nghiệp, sự lựa chọn giữa các thuật toán hai giai đoạn như Faster R-CNN (ưu tiên độ chính xác) và một giai đoạn như YOLO (ưu tiên tốc độ thời gian thực) quyết định khả năng triển khai thành công trên dây chuyền tốc độ cao.
1. Vai trò thiết yếu của Phát hiện đối tượng trong Sản xuất Công nghiệp
Trong kỷ nguyên Machine Vision hiện đại, việc chỉ xác định một hình ảnh thuộc loại “Đạt” hay “Không đạt” (Classification) là không đủ. Nhu cầu thực tế của sản xuất công nghiệp đòi hỏi một khả năng phân tích chi tiết và có tính định vị cao hơn: khả năng Phát hiện đối tượng (Object Detection).
Định nghĩa: Phát hiện đối tượng là một kỹ thuật học sâu không chỉ gán nhãn cho toàn bộ hình ảnh, mà còn xác định và khoanh vùng (Localization) vị trí của một hoặc nhiều đối tượng quan tâm (Objects of Interest) bằng một Hộp giới hạn (Bounding Box). Nó là sự kết hợp của hai nhiệm vụ: Phân loại (đối tượng đó là gì) và Định vị (đối tượng đó nằm ở đâu).
Tầm quan trọng trong Machine Vision Công nghiệp: Khả năng cung cấp tọa độ chính xác của vật thể hoặc lỗi (Bounding Box) là nền tảng cho nhiều ứng dụng tự động hóa tiên tiến:
- Kiểm soát chất lượng định vị (Pinpoint Quality Control): Thay vì chỉ báo cáo “sản phẩm này có lỗi”, hệ thống Machine Vision sử dụng Phát hiện đối tượng có thể chỉ ra chính xác “Lỗi bong tróc nằm tại góc trên bên phải, tọa độ (x1,y1) đến (x2,y2)”. Điều này giúp loại bỏ phỏng đoán và tăng tốc độ xử lý lỗi.
- Robot định hướng (Robot Guidance) cho các tác vụ Pick & Place: Trong kho hàng hoặc trên dây chuyền lắp ráp, robot cần biết chính xác tọa độ (x,y,z) và hướng (Orientation) của linh kiện để gắp và đặt. Các mô hình YOLO và Faster R-CNN cung cấp tọa độ 2D chính xác, thường được kết hợp với thị giác 3D để đưa ra hướng dẫn hành động cho robot.
- Kiểm tra lắp ráp và đếm số lượng: Mô hình có thể đồng thời Phát hiện đối tượng và đếm số lượng các bộ phận nhỏ (ví dụ: đinh ốc, linh kiện) trên một bảng mạch in (PCB) để đảm bảo lắp ráp đầy đủ.
Thách thức: Bài toán Phát hiện đối tượng phức tạp hơn nhiều so với phân loại đơn thuần. Nó yêu cầu mô hình phải đạt sự cân bằng hoàn hảo giữa Độ chính xác (Accuracy) (đo bằng IOU – Intersection over Union và mAP – mean Average Precision) và Tốc độ suy luận (Inference Speed) (đo bằng FPS – Frames Per Second). Trong môi trường sản xuất công nghiệp tốc độ cao, đôi khi tốc độ được ưu tiên hơn một chút so với độ chính xác tuyệt đối, tạo nên cuộc cạnh tranh giữa các kiến trúc YOLO và Faster R-CNN.

2. Các phương pháp Phát hiện đối tượng hàng đầu và sự phân loại kiến trúc
Sự phát triển của Phát hiện đối tượng đã dẫn đến sự ra đời của hai triết lý kiến trúc chính, mỗi triết lý có những ưu điểm đặc thù, phù hợp với các loại nhu cầu khác nhau trong Machine Vision Công nghiệp.
2.1. Mô hình hai giai đoạn (Two-Stage Detectors) – Đại diện: Faster R-CNN
Mô hình hai giai đoạn như Faster R-CNN là các mô hình kế thừa từ R-CNN và Fast R-CNN. Chúng hoạt động theo một quy trình kiểm tra kép, cho phép độ chính xác cao nhưng đánh đổi bằng tốc độ.
Nguyên tắc hoạt động:
- Giai đoạn 1 (Đề xuất Vùng): Mô hình tạo ra một tập hợp các đề xuất về các khu vực có khả năng chứa đối tượng.
- Giai đoạn 2 (Phân loại và Tinh chỉnh): Các vùng đề xuất này được phân loại cụ thể và Hộp giới hạn được tinh chỉnh lại để khớp chính xác với đối tượng.
Đặc điểm: Nhờ quá trình kiểm tra hai bước này, Faster R-CNN đạt độ chính xác cao nhất (High Accuracy) và mAP ấn tượng, đặc biệt với các đối tượng nhỏ và xếp chồng (Occluded Objects). Tuy nhiên, do phải thực hiện hai bước tính toán, tốc độ xử lý chậm hơn.
2.2. Mô hình một giai đoạn (One-Stage Detectors) – Đại diện: YOLO
Mô hình một giai đoạn, tiên phong là YOLO (You Only Look Once), loại bỏ bước đề xuất vùng riêng biệt và xử lý tất cả trong một lần chạy duy nhất.
- Nguyên tắc hoạt động: Xử lý toàn bộ hình ảnh trong một lần chạy duy nhất (Single Pass) thông qua mạng CNN để dự đoán đồng thời cả Bounding Box và Lớp.
- Đặc điểm: Triết lý “Nhìn một lần” này giúp YOLO đạt được tốc độ thời gian thực (Real-Time Speed), có thể lên tới hàng trăm FPS. Dù ban đầu độ chính xác có thể thấp hơn Faster R-CNN, nhưng các phiên bản mới của YOLO đã thu hẹp đáng kể khoảng cách này.

3. Phân tích Chuyên sâu Mô hình Two-Stage: Faster R-CNN
Faster R-CNN đại diện cho triết lý ưu tiên độ chính xác trong Phát hiện đối tượng. Mô hình này đặc biệt quan trọng trong các ứng dụng Machine Vision Công nghiệp nơi rủi ro của lỗi bỏ sót (False Negatives) là không thể chấp nhận được, chẳng hạn như kiểm tra các linh kiện đắt tiền hoặc các bộ phận có kích thước siêu nhỏ.
3.1. Kiến trúc và cơ chế hoạt động
Kiến trúc Faster R-CNN được xây dựng trên một mạng nơ-ron tích chập (CNN) cơ sở (thường là VGG hoặc ResNet) để trích xuất đặc trưng, và bao gồm hai thành phần cải tiến chính:
Mạng đề xuất vùng (Region Proposal Network – RPN): Đây là cải tiến đột phá so với các phiên bản R-CNN trước. Thay vì sử dụng thuật toán thủ công như Selective Search, Faster R-CNN sử dụng một mạng CNN nhỏ để tự học cách đề xuất các vùng có khả năng chứa đối tượng.
Vai trò của RPN: RPN quét hình ảnh và tạo ra hàng ngàn Anchors (Hộp giới hạn có kích thước và tỷ lệ khung hình được xác định trước) tại mỗi vị trí. Sau đó, nó dự đoán xác suất mỗi Anchor có chứa đối tượng (“Foreground”) hay không (“Background”). Bằng cách này, RPN cung cấp một số lượng đề xuất vùng chất lượng cao và có thể tùy chỉnh được cho Machine Vision Công nghiệp.
ROI Pooling/Align: Các đề xuất vùng (Regions of Interest – ROI) được tạo ra bởi RPN có kích thước khác nhau. Để đưa chúng vào lớp Phân loại và Hồi quy Bounding Box cuối cùng (thường là một mạng Fully Connected), chúng cần được chuẩn hóa về cùng một kích thước.
- ROI Pooling: Phân chia vùng đề xuất thành lưới và gộp giá trị Max/Average.
- ROI Align (cải tiến): Sử dụng phép nội suy để lấy mẫu chính xác hơn, tránh lỗi làm tròn số của ROI Pooling, giúp tăng độ chính xác đặc biệt với các đối tượng nhỏ.
3.2. Ưu và nhược điểm trong Sản xuất
Ưu điểm:
- Độ chính xác rất cao (mAP): Là chuẩn mực để so sánh hiệu suất với các mô hình khác.
- Khả năng xử lý tốt các đối tượng nhỏ, dày đặc (Dense Objects) hoặc bị xếp chồng (Occluded Objects). Giai đoạn RPN và tinh chỉnh Bounding Box giúp nó tập trung cao độ vào từng chi tiết.
- Rất lý tưởng cho các ứng dụng kiểm tra chi tiết ngoại tuyến (Off-line Detailed Inspection) hoặc các quy trình kiểm soát chất lượng quan trọng, nơi độ chính xác 99.99% là bắt buộc, ví dụ: kiểm tra khuyết tật mối hàn, kiểm tra tính toàn vẹn của chip bán dẫn.

Nhược điểm:
- Tốc độ suy luận chậm hơn: Do kiến trúc hai giai đoạn, Faster R-CNN thường đạt tốc độ dưới 10 FPS trên CPU thông thường và hiếm khi vượt quá 30−40 FPS ngay cả trên GPU mạnh.
- Yêu cầu tài nguyên tính toán lớn: Khó triển khai trên thiết bị biên (Edge Devices) có giới hạn năng lượng và bộ nhớ.
4. Phân tích Chuyên sâu Mô hình One-Stage: YOLO (You Only Look Once)
YOLO là mô hình đã định nghĩa lại khái niệm tốc độ trong Phát hiện đối tượng. Triết lý “Nhìn một lần” của YOLO giúp nó trở thành giải pháp lý tưởng cho các ứng dụng Machine Vision Công nghiệp yêu cầu tốc độ thời gian thực tuyệt đối, nơi băng chuyền chạy ở tốc độ cao và cần phản ứng ngay lập tức.
4.1. Kiến trúc và triết lý “Nhìn một lần”
YOLO loại bỏ sự cần thiết của RPN. Nó xử lý toàn bộ bài toán Phát hiện đối tượng chỉ trong một lần duy nhất qua mạng nơ-ron (End-to-End).
Lưới dự đoán (Grid System): YOLO chia hình ảnh thành một lưới S×S (ví dụ: 13×13). Mỗi ô lưới (Grid Cell) chịu trách nhiệm cho các đối tượng có tâm nằm trong ô đó.
Dự đoán đồng thời: Mỗi ô lưới dự đoán đồng thời:
- Tọa độ Hộp giới hạn (x,y,w,h).
- Độ tự tin (Confidence Score) đối với việc Hộp giới hạn đó có chứa đối tượng hay không.
- Xác suất lớp (Class Probabilities) cho đối tượng đó.
Ưu điểm của Single Pass: Vì tất cả các dự đoán (vị trí, kích thước, lớp) đều được thực hiện cùng một lúc, YOLO loại bỏ được sự chậm trễ của mô hình hai giai đoạn, giúp nó đạt tốc độ cao hơn từ 10 đến 100 lần.
Các phiên bản mới (YOLOv5, YOLOv8): Các phiên bản sau này đã khắc phục nhược điểm ban đầu của YOLO (độ chính xác thấp hơn, khó phát hiện đối tượng nhỏ) thông qua:
- Sử dụng Feature Pyramid Networks (FPN) hoặc Path Aggregation Network (PANet) để kết hợp các đặc trưng từ nhiều cấp độ sâu khác nhau, giúp cải thiện khả năng phát hiện các đối tượng ở nhiều quy mô (Scale) khác nhau.
- Cải tiến các hàm mất mát (Loss Function) để tinh chỉnh Bounding Box chính xác hơn (ví dụ: sử dụng CIoU Loss, DIoU Loss).
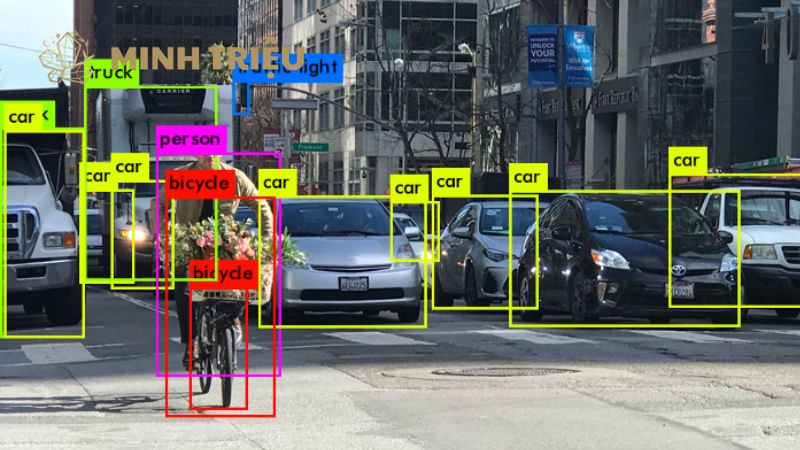
4.2. Ưu và nhược điểm trong Sản xuất
Ưu điểm:
- Tốc độ suy luận cực nhanh: Có thể đạt 60 FPS, 100 FPS, thậm chí 200+ FPS trên GPU chuyên dụng, đáp ứng yêu cầu thời gian thực của các băng chuyền hiện đại.
- Rất phù hợp cho các ứng dụng định vị đối tượng cho robot, giám sát chuyển động và kiểm soát chất lượng tốc độ cao (ví dụ: phân loại sản phẩm trên băng tải, đếm linh kiện đang rơi).
- Kiến trúc đơn giản hơn, dễ dàng tối ưu hóa và triển khai trên thiết bị biên.
Nhược điểm:
- Độ chính xác ban đầu có thể thấp hơn Faster R-CNN (dù khoảng cách đã được thu hẹp).
- Khó khăn hơn trong việc phát hiện các đối tượng rất nhỏ hoặc xếp chồng lên nhau (Occluded Objects) vì mỗi ô lưới chỉ có thể dự đoán một số lượng Hộp giới hạn giới hạn.
5. Chiến lược Lựa chọn và Tối ưu hóa cho Machine Vision Công nghiệp
Việc chọn và triển khai mô hình Phát hiện đối tượng thành công trong Machine Vision Công nghiệp không chỉ là việc chọn thuật toán tốt nhất, mà là chọn thuật toán phù hợp nhất và tối ưu hóa nó cho môi trường sản xuất thực tế.
5.1. Tiêu chí lựa chọn mô hình
Quyết định nên dùng YOLO hay Faster R-CNN phụ thuộc vào các yếu tố ràng buộc kỹ thuật:
- Tốc độ dây chuyền (FPS): Đây là tiêu chí hàng đầu. Nếu tốc độ yêu cầu trên 50 FPS, YOLO (hoặc các mô hình một giai đoạn) là lựa chọn bắt buộc. Nếu tốc độ chậm hơn (<10 FPS), Faster R-CNN sẽ mang lại lợi ích về độ chính xác.
- Kích thước đối tượng/lỗi: Nếu lỗi/đối tượng rất nhỏ (dưới 1% diện tích ảnh) và độ chính xác pixel là quan trọng, Faster R-CNN truyền thống hoặc các phiên bản YOLO mới nhất có tích hợp FPN/PANet (ví dụ: YOLOv8) nên được cân nhắc, vì chúng xử lý chi tiết tốt hơn.
- Ngân sách phần cứng: YOLO (do kiến trúc nhẹ hơn) đòi hỏi ít tài nguyên tính toán hơn và thường dễ dàng triển khai trên thiết bị biên (Edge Devices) như NVIDIA Jetson hoặc Intel Movidius, giúp tiết kiệm chi phí đầu tư.

5.2. Kỹ thuật Tối ưu hóa Mô hình (Model Optimization)
Mô hình sau khi Huấn luyện mô hình phải được tối ưu hóa để đạt được tốc độ suy luận nhanh nhất trên phần cứng mục tiêu.
- Transfer Learning: Áp dụng cho cả YOLO và Faster R-CNN để giảm thời gian huấn luyện và nhu cầu dữ liệu. Bắt đầu với các trọng số đã được huấn luyện trên ImageNet hoặc COCO sẽ cải thiện đáng kể khả năng tổng quát hóa ban đầu của mô hình.
- Lượng tử hóa (Quantization): Đây là kỹ thuật then chốt trong tối ưu hóa CNN. Nó giảm độ chính xác của các trọng số từ 32-bit Floating-point (Float32) xuống 8-bit Integer (Int8). Việc này giúp giảm 4 lần kích thước mô hình và tăng tốc độ suy luận từ 2 đến 4 lần trên các phần cứng có khả năng xử lý Int8, một yếu tố cực kỳ quan trọng đối với tốc độ thời gian thực.
- Công cụ tăng tốc: Sử dụng các công cụ tăng tốc chuyên dụng như TensorRT (NVIDIA) hoặc OpenVINO (Intel) để biên dịch và tối ưu hóa mô hình đã Huấn luyện mô hình (ví dụ: từ định dạng PyTorch/TensorFlow sang định dạng tối ưu hóa như ONNX) nhằm tận dụng tối đa kiến trúc phần cứng chuyên dụng.

5.3. Chuẩn bị Dữ liệu chuyên biệt cho Detection
Chất lượng dán nhãn là yếu tố sống còn cho Phát hiện đối tượng.
- Dán nhãn Bounding Box: Phải đảm bảo tọa độ Hộp giới hạn x1,y1,x2,y2 phải cực kỳ chính xác. Lỗi dán nhãn box dù nhỏ cũng sẽ làm hỏng khả năng định vị của mô hình, dẫn đến lỗi IOU thấp.
- Xử lý mẫu âm tính (Negative Samples): Đưa các hình ảnh không có đối tượng, hoặc hình ảnh “gần lỗi” vào huấn luyện. Việc này giúp mô hình học cách phân biệt rõ ràng giữa “không có gì” và “có đối tượng”, từ đó giảm đáng kể cảnh báo giả (False Positives), một vấn đề đau đầu trong kiểm soát chất lượng công nghiệp.
- Tăng cường dữ liệu (Data Augmentation) phù hợp: Sử dụng các kỹ thuật tăng cường Bounding Box như cắt, dán (Cut-Paste), xoay (có điều kiện để tránh biến dạng box), và thay đổi độ sáng để giúp mô hình chịu được sự biến đổi của môi trường sản xuất công nghiệp.
6. Kết luận
Faster R-CNN và YOLO đại diện cho hai triết lý tối ưu hóa chủ đạo trong Machine Vision: Độ chính xác tối đa và Tốc độ tối đa. Sự lựa chọn mô hình luôn phụ thuộc vào yêu cầu cụ thể của từng dây chuyền sản xuất công nghiệp. Tuy nhiên, xu hướng phát triển chung là các mô hình thế hệ mới tiếp tục thu hẹp khoảng cách giữa tốc độ (YOLO) và độ chính xác (Faster R-CNN), hướng tới các kiến trúc linh hoạt hơn (như Transformer-based Detectors) có khả năng thích ứng với mọi điều kiện. Việc làm chủ Phát hiện đối tượng là bước ngoặt quan trọng, giúp các nhà máy hiện đại hóa quy trình kiểm soát chất lượng và thúc đẩy tự động hóa robot lên một tầm cao mới.