
Thị giác máy (Machine Vision)
Học Tăng Cường (Reinforcement Learning) trong Thị Giác Máy: Tối Ưu Hóa Quyết Định Tự Động Hóa trong Sản Xuất Công Nghiệp

Sản xuất công nghiệp hiện đại đòi hỏi các hệ thống Tự động hóa có khả năng ra quyết định chiến lược, học hỏi từ môi trường phức tạp và vượt qua giới hạn của lập trình truyền thống vốn chỉ có thể xử lý các tình huống cố định và đã biết. Việc tích hợp Học tăng cường (Reinforcement Learning – RL) vào Machine Vision (Thị giác máy) đánh dấu một bước ngoặt quan trọng, cho phép máy móc không chỉ “nhìn” mà còn “suy nghĩ” và “hành động” một cách tối ưu trong các tình huống không xác định.
Thị giác máy cung cấp dữ liệu nhận thức (Perception Data) một cách liên tục, chuyển đổi môi trường vật lý thành State (trạng thái môi trường) có thể hiểu được cho các thuật toán AI/Deep Learning. Thị trường toàn cầu đang chứng kiến sự tăng trưởng mạnh mẽ của các giải pháp RL vì nó cho phép hệ thống tự điều chỉnh tham số và chính sách hành động để đạt được mục tiêu sản xuất cao nhất và tối ưu hóa toàn diện. Bài viết này sẽ giải thích nguyên lý cốt lõi của Học tăng cường trong Thị giác máy như là cơ quan cảm giác trong khuôn khổ RL, và minh họa kiến trúc tích hợp cần thiết cho sản xuất công nghiệp.
1. Cơ sở Lý thuyết RL và Vai trò trong Machine Vision
Học Tăng Cường (RL) là lĩnh vực của AI/Deep Learning dựa trên khái niệm Agent, Environment, State, Action và Reward, cho phép hệ thống học cách đưa ra chuỗi quyết định tối ưu thông qua cơ chế thử và sai. Mô hình RL tồn tại trong một chu kỳ lặp liên tục, trong đó Agent (chủ thể ra quyết định) quan sát State (trạng thái) của Environment (môi trường), thực hiện Action (hành động), nhận Reward (phần thưởng) hoặc Penalty (hình phạt), và cập nhật chính sách (Policy) để tối đa hóa tổng phần thưởng tích lũy theo thời gian. Cơ chế học tập này mô phỏng cách thức sinh vật sống học tập từ kinh nghiệm, biến RL thành công cụ lý tưởng cho Tự động hóa và ra quyết định chiến lược trong môi trường động.
Sự tích hợp này cho phép Agent RL có được nhận thức toàn diện về môi trường vật lý, vượt qua giới hạn của các cảm biến định lượng đơn thuần. Các mô hình RL cốt lõi như DQN (Deep Q-Network) hoặc PPO (Proximal Policy Optimization) đang được phân tích và áp dụng rộng rãi cho Machine Vision trong sản xuất công nghiệp. DQN sử dụng Deep Learning để ước tính giá trị của các hành động (Q-Value) trong các State quan sát được từ hình ảnh, phù hợp cho các bài toán có không gian hành động rời rạc (ví dụ: bật/tắt máy, thay đổi tốc độ).

PPO là thuật toán Policy Gradient cân bằng giữa việc khám phá (Exploration) và khai thác (Exploitation), thường được ưu tiên cho các nhiệm vụ có không gian hành động liên tục như điều khiển chuyển động chính xác của Robot cộng tác. Việc lựa chọn mô hình RL phụ thuộc vào tính chất của nhiệm vụ và môi trường sản xuất công nghiệp.
2. Kiến trúc Tích hợp RL- Machine Vision trong Sản xuất
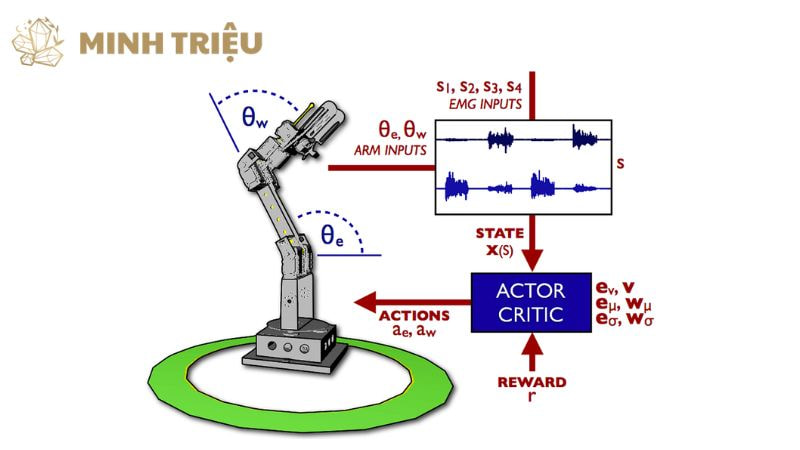
Kiến trúc Cảm biến-Hành động (Sensor-Action Architecture) mô tả luồng dữ liệu tuần tự từ Camera Machine Vision đến Mô hình RL và đến bộ điều khiển vật lý (Actuator/Robot), tạo thành một vòng lặp điều khiển khép kín. Vòng lặp này bắt đầu khi Thị giác máy thu thập hình ảnh và xử lý nó thành State (trạng thái), sau đó truyền State đến Agent RL. Agent RL sử dụng chính sách đã học để xác định hành động tối ưu và gửi tín hiệu điều khiển đến Actuator hoặc Robot cộng tác. Actuator thực hiện hành động vật lý trên dây chuyền, dẫn đến sự thay đổi của môi trường, và vòng lặp tiếp tục với State mới từ Machine Vision, đảm bảo phản ứng trong thời gian thực.
Quá trình suy luận và ra quyết định của RL cần được thực hiện tại Điện toán biên (Edge Computing) để đảm bảo độ trễ thấp (Latency) và phản ứng trong thời gian thực cho môi trường sản xuất công nghiệp tốc độ cao. Việc di chuyển quá trình xử lý từ Cloud về gần nguồn dữ liệu (Camera) giảm thời gian truyền tải đáng kể, cho phép Agent RL đưa ra hành động trong mili giây.

Mô hình RL sau khi được huấn luyện sẽ được triển khai trên các bộ xử lý Edge mạnh mẽ (ví dụ: GPU/TPU nhúng), đảm bảo Tự động hóa cục bộ và độ tin cậy cao ngay cả khi kết nối mạng bị gián đoạn. Điện toán biên là yếu tố quyết định đối với sự thành công của các ứng dụng RL có yêu cầu phản hồi tức thì. Việc xác định cách Thị giác máy biến đổi hình ảnh phức tạp thành State có ý nghĩa cho Agent RL và cách các hành động được ánh xạ sang điều khiển robot hoặc máy móc là bước thiết kế hệ thống then chốt.
Machine Vision thực hiện các tác vụ như phát hiện vật thể (Object Detection), phân đoạn hình ảnh (Segmentation) và ước tính tư thế (Pose Estimation) để trích xuất dữ liệu định lượng (ví dụ: tọa độ x,y,z, góc θ, loại lỗi). Dữ liệu này chính là State vector mà Agent RL sử dụng để học chính sách. Hành động được Agent đưa ra là các lệnh điều khiển máy móc, chẳng hạn như thay đổi tốc độ của băng chuyền, điều chỉnh lực siết của công cụ, hoặc thay đổi quỹ đạo của Robot cộng tác.
| Thành phần Kiến trúc | Chức năng trong RL-MV | Yêu cầu Kỹ thuật |
|---|---|---|
| Camera Machine Vision | Cảm biến, cung cấp State (hình ảnh) trong thời gian thực | Độ phân giải cao, Tốc độ khung hình (FPS) cao, Ánh sáng đồng nhất |
| Edge Computing Node | Thực hiện quá trình suy luận của Agent RL và xử lý hình ảnh | GPU/TPU nhúng, Độ trễ thấp (Latency) |
| Agent RL Model | Học chính sách hành động và đưa ra quyết định tối ưu | Thuật toán AI/Deep Learning (DQN, PPO), Bộ nhớ đệm kinh nghiệm (Replay Buffer) |
| Actuator/Robot | Thực hiện Action (hành động vật lý) được quyết định bởi Agent | Tốc độ phản hồi nhanh, Độ chính xác cao, Giao diện điều khiển số (Digital Interface) |
3. Ứng dụng Đột phá của Học Tăng Cường trong MV Công nghiệp
Học Tăng Cường đã tạo ra những bước tiến đột phá trong sản xuất công nghiệp bằng cách nâng cao khả năng Tự động hóa và thích ứng của hệ thống Thị giác máy trong các tình huống phức tạp.
3.1. Điều khiển Robot Cộng tác (Robotics & Collaboration)
Robot cộng tác cần thực hiện các nhiệm vụ phức tạp và thay đổi liên tục như gắp đặt vật thể (Pick-and-Place) trong môi trường không cố định, vượt xa khả năng của lập trình định sẵn. RL cung cấp một giải pháp bằng cách sử dụng dữ liệu thị giác để học chính sách (Policy) điều khiển chuyển động tối ưu, cho phép Robot thích ứng với vị trí và hình dạng của vật thể trong thời gian thực.
Agent RL được huấn luyện trong môi trường mô phỏng và sử dụng hình ảnh từ Machine Vision như là State để điều khiển tay gắp của Robot di chuyển một cách chính xác và linh hoạt hơn so với các giải pháp điều khiển cổ điển. Giá trị này dẫn đến Tự động hóa linh hoạt hơn, đảm bảo Robot cộng tác có thể xử lý các biến thể về sản phẩm hoặc môi trường một cách hiệu quả, giảm đáng kể thời gian lập trình Robot cho các nhiệm vụ mới.

3.2. Kiểm soát Chất lượng Thích ứng (Adaptive Quality Control)
Kiểm soát chất lượng (QC) truyền thống chỉ có thể “phân loại” lỗi sau khi chúng đã xảy ra, và không thể điều chỉnh quy trình để ngăn chặn lỗi tái diễn một cách chủ động. Agent RL cung cấp khả năng chuyển đổi từ QC thụ động sang QC chủ động bằng cách sử dụng kết quả Machine Vision (lỗi/không lỗi) như là Reward/Penalty để điều chỉnh các tham số của dây chuyền sản xuất.
Ví dụ, Agent RL có thể quan sát rằng sự kết hợp của tốc độ băng chuyền và áp suất hàn đã tạo ra sản phẩm lỗi, và sau đó Agent sẽ học cách điều chỉnh tốc độ hoặc áp suất trong thời gian thực để tối ưu hóa Tối ưu hóa Quy trình Sản xuất. Việc tối ưu hóa hiệu suất này dẫn đến giảm đáng kể Defect Rate, giúp doanh nghiệp tiết kiệm chi phí nguyên vật liệu và nâng cao chất lượng sản phẩm cuối cùng.
3.3. Bảo trì Thông minh (Intelligent Maintenance Scheduling)
Lịch trình Bảo trì dự đoán thường chỉ dựa trên dữ liệu cảm biến thô (nhiệt độ, rung động) chứ không phải tình trạng vật lý trực quan thực tế của thiết bị, dẫn đến dự đoán không chính xác. Thị giác máy cung cấp trạng thái suy thoái (ví dụ: độ mòn bề mặt, vết nứt, rò rỉ dầu) và Agent RL học cách quyết định thời điểm Bảo trì tối ưu từ dữ liệu này.
Agent RL nhận Penalty khi Downtime xảy ra và nhận Reward khi máy móc được Bảo trì trước khi hỏng hóc lớn xảy ra, nhưng không quá sớm. Điều này nâng cao độ chính xác và hiệu quả của chiến lược Bảo trì dự đoán, bảo đảm tối đa hóa tuổi thọ thiết bị và giảm thiểu dừng máy (Downtime) không cần thiết.
4. Thách thức và Tiềm năng Phát triển
Thách thức về Mô phỏng (Sim-to-Real Gap) là rào cản kỹ thuật lớn nhất trong việc triển khai RL vào sản xuất công nghiệp. Khó khăn này phát sinh từ việc chuyển các chính sách RL được học trong môi trường mô phỏng (Simulation) sang môi trường vật lý thực tế vì sự khác biệt về nhiễu cảm biến, độ trễ cơ học, và biến đổi ánh sáng. Việc khắc phục thách thức này đòi hỏi các kỹ thuật như Tăng cường ngẫu nhiên (Domain Randomization) và Học Tăng cường thích ứng (Adaptive RL), nhằm đảm bảo mô hình hoạt động ổn định và hiệu quả trong thế giới thực.
Thách thức về An toàn và Giải thích được (Explainability) đặt ra các mối quan tâm đạo đức và vận hành quan trọng, vì tính chất hộp đen của AI/Deep Learning khiến các quyết định của Agent RL khó được giải thích. Trong môi trường sản xuất công nghiệp, việc đảm bảo các quyết định của Agent RL là an toàn và có thể được giải thích là tối quan trọng để đáp ứng các tiêu chuẩn an toàn và quy định pháp lý.
Các giải pháp đang được nghiên cứu bao gồm việc áp dụng các mô hình AI có thể giải thích được (XAI) và thiết lập các giới hạn hành động an toàn (Safety Constraints) trong hàm Reward. Tiềm năng Tương lai hướng đến Nhà máy thông minh hoàn toàn tự trị với Học tăng cường đóng vai trò là “bộ não” điều hành. RL sẽ được áp dụng không chỉ cho các tác vụ cục bộ như điều khiển robot mà còn cho việc tối ưu hóa chuỗi cung ứng và thiết kế sản phẩm thông minh.
5. Kết luận
Học tăng cường trong Thị giác máy, chuyển đổi nó từ hệ thống kiểm tra tĩnh thành hệ thống ra quyết định và điều khiển động trong sản xuất công nghiệp. Sự kết hợp này mở ra khả năng Tự động hóa không giới hạn, cho phép Robot cộng tác thực hiện các tác vụ phức tạp một cách linh hoạt và Tối ưu hóa Quy trình Sản xuất được thực hiện trong thời gian thực nhờ Kiểm soát chất lượng thích ứng. Việc khắc phục các thách thức như Sim-to-Real Gap và Explainability là cần thiết để hiện thực hóa tiềm năng này.