
Robot công nghiệp
Robot Học Tăng Cường (Reinforcement Learning): Nâng Tầm Trí Tuệ Cánh Tay Robot Trong Sản Xuất Công Nghiệp

Robot học tăng cường (Reinforcement Learning – RL) là một lĩnh vực của học máy cho phép hệ thống tự học cách đưa ra quyết định tối ưu thông qua quá trình thử và sai trong một môi trường tương tác. Phương pháp này tương tự cách con người học hỏi từ kinh nghiệm.Tiềm năng của RL trong việc giúp cánh tay robot tự động học hỏi các kỹ năng phức tạp, thích nghi với những thay đổi và bất định của môi trường sản xuất mà không cần lập trình thủ công chi tiết, là vô cùng lớn. Bài viết này sẽ đi sâu vào nguyên lý hoạt động của RL.
1. Robot Học Tăng Cường: Nguyên Lý Hoạt Động Cơ Bản
Robot học tăng cường hoạt động dựa trên nguyên lý học tập qua tương tác, nơi một tác tử thực hiện hành động trong một môi trường và nhận phản hồi dưới dạng phần thưởng để tối ưu hóa hành vi của mình.
Các thành phần chính của hệ thống RL:
Một hệ thống RL được cấu thành từ nhiều yếu tố tương tác với nhau để tạo nên quá trình học tập của tác tử.
- Tác tử (Agent): Trong ngữ cảnh robot học, tác tử chính là cánh tay robot hoặc bộ điều khiển robot được trang bị các thuật toán RL. Tác tử là thực thể đưa ra các quyết định và thực hiện hành động trong môi trường.
- Môi trường (Environment): Môi trường là không gian tương tác mà tác tử tồn tại và hoạt động. Đối với cánh tay robot, môi trường có thể là dây chuyền sản xuất tự động, các vật thể cần thao tác, các chướng ngại vật tiềm tàng, và các yếu tố vật lý khác như lực hoặc ma sát.
- Trạng thái (State): Trạng thái là tập hợp các thông tin mô tả tình hình hiện tại của môi trường và tác tử tại một thời điểm nhất định. Đối với một robot, trạng thái có thể bao gồm vị trí và vận tốc của các khớp, lực tác động lên bộ phận gắp, hình dạng và vị trí của vật phẩm, hay dữ liệu từ các cảm biến.
- Hành động (Action): Hành động là các quyết định hoặc chuyển động cụ thể mà tác tử có thể thực hiện trong một trạng thái nhất định. Ví dụ, đối với cánh tay robot, các hành động có thể là điều khiển góc quay của từng khớp, di chuyển bộ phận gắp, gắp một vật thể, hoặc đặt vật thể xuống.
- Phần thưởng (Reward): Phần thưởng là tín hiệu phản hồi tích cực hoặc tiêu cực mà tác tử nhận được từ môi trường sau khi thực hiện một hành động. Phần thưởng này đóng vai trò định hướng quá trình học, khuyến khích tác tử lặp lại những hành động mang lại kết quả mong muốn và tránh những hành động không hiệu quả. Ví dụ, hoàn thành tác vụ gắp đặt thành công có thể mang lại phần thưởng lớn, trong khi va chạm có thể dẫn đến hình phạt.
Quy trình học tập qua thử và sai:
Quy trình học tập của RL diễn ra thông qua một vòng lặp liên tục giữa việc khám phá và khai thác, dẫn đến việc tối ưu hóa hành vi.

- Khám phá (Exploration) và Khai thác (Exploitation): Đây là sự cân bằng cốt lõi trong RL. Khám phá là quá trình tác tử thử các hành động mới, thậm chí là ngẫu nhiên, để tìm kiếm những phần thưởng tiềm năng chưa biết.
- Khai thác là quá trình tác tử sử dụng kiến thức đã học được để thực hiện các hành động mà nó tin rằng sẽ tối đa hóa phần thưởng. Việc tìm ra sự cân bằng phù hợp là rất quan trọng để robot có thể học hiệu quả mà không bị mắc kẹt ở một giải pháp dưới tối ưu.
- Hàm giá trị (Value Function) và Chính sách (Policy): Hàm giá trị mô tả mức độ tốt của một trạng thái hoặc một hành động cụ thể trong một trạng thái nhất định, dựa trên tổng phần thưởng dự kiến trong tương lai.
- Chính sách là một chiến lược mà tác tử sử dụng để quyết định hành động nào sẽ thực hiện trong một trạng thái cụ thể. Quá trình học RL về cơ bản là việc tác tử học cách ước estims hàm giá trị và phát triển một chính sách tối ưu để đạt được mục tiêu.
Các thuật toán RL phổ biến trong Robot học:
Nhiều thuật toán RL đã được phát triển để giải quyết các vấn đề khác nhau, và một số trong số đó đặc biệt hiệu quả trong lĩnh vực robot học.
- Q-learning: Q-learning là một thuật toán học giá trị hành động cho phép tác tử học một hàm Q (giá trị Q) ước tính giá trị của việc thực hiện một hành động cụ thể trong một trạng thái nhất định. Nó hoạt động bằng cách cập nhật giá trị Q dựa trên phần thưởng nhận được và giá trị Q tối đa của trạng thái tiếp theo.
- Policy Gradients (PG) / Proximal Policy Optimization (PPO): Các thuật toán Policy Gradients học trực tiếp một chính sách tối ưu, nghĩa là chúng học cách ánh xạ trực tiếp từ trạng thái sang hành động. PPO là một biến thể phổ biến của PG được biết đến với sự ổn định và hiệu quả, thường được sử dụng trong các tác vụ robot phức tạp.
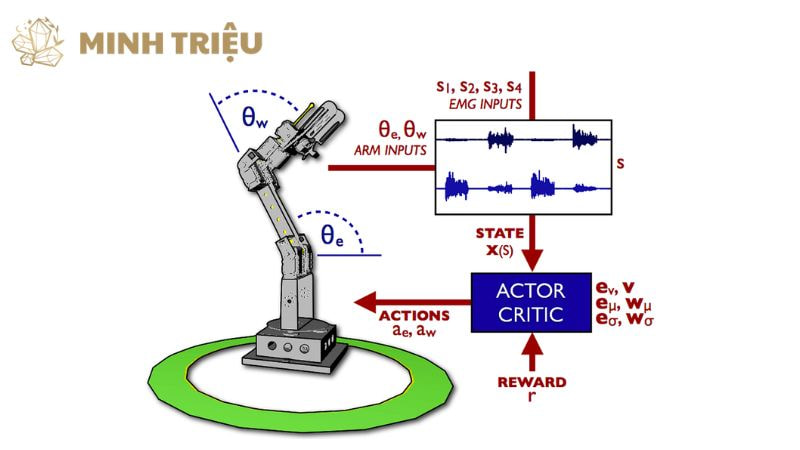
- Actor-Critic methods: Các phương pháp Actor-Critic kết hợp cả việc học chính sách (Actor) và học giá trị (Critic). Actor chịu trách nhiệm chọn hành động, trong khi Critic đánh giá chất lượng của hành động đó, cung cấp phản hồi để Actor có thể cải thiện chính sách của mình. Sự kết hợp này thường dẫn đến quá trình học hiệu quả và ổn định hơn.
2. Ứng Dụng Của Robot Học Tăng Cường Cho Cánh Tay Robot Công Nghiệp
Robot học tăng cường mở ra những khả năng mới cho cánh tay robot công nghiệp, cho phép chúng thực hiện các tác vụ phức tạp, thích nghi với môi trường thay đổi và tối ưu hóa hiệu suất một cách chưa từng có.

Tối ưu hóa các tác vụ phức tạp và biến động:
RL là công cụ mạnh mẽ để tối ưu hóa các tác vụ robot phức tạp và biến động, vượt qua giới hạn của lập trình truyền thống.
- Gắp đặt linh hoạt (Picky-Place/Bin Picking): Cánh tay robot có thể học cách gắp các vật thể có hình dạng, kích thước và vị trí ngẫu nhiên từ thùng chứa (bin picking), một nhiệm vụ cực kỳ khó khăn đối với các hệ thống lập trình cứng nhắc. Robot gắp đặt sử dụng RL có thể tự điều chỉnh góc độ và lực gắp để xử lý đa dạng các vật phẩm.
- Lắp ráp thích ứng (Adaptive Assembly): RL cho phép robot lắp ráp học cách điều chỉnh chuyển động để khớp các bộ phận có dung sai sản xuất nhỏ hoặc sai lệch vị trí. Robot có thể tự tìm ra các chiến lược để vượt qua sự không hoàn hảo, tăng độ chính xác lặp lại và giảm lỗi.
- Hàn robot phức tạp (Complex Robotic Welding): Các robot hàn có thể sử dụng RL để học cách điều chỉnh đường hàn, tốc độ di chuyển, nhiệt độ và lượng vật liệu nạp dựa trên đặc tính vật liệu, hình dạng chi tiết gia công, và điều kiện môi trường. Điều này dẫn đến các mối hàn chất lượng cao hơn và linh hoạt hơn.
Thích nghi với môi trường thay đổi và không chắc chắn:
Khả năng thích nghi của RL giúp cánh tay robot đối phó hiệu quả với môi trường sản xuất năng động và không chắc chắn.
- Xử lý lỗi và bất thường: Robot được huấn luyện bằng RL có thể học cách nhận diện và phản ứng một cách thông minh với các tình huống không mong muốn, chẳng hạn như một vật thể bị rơi, một linh kiện bị kẹt, hoặc một máy móc khác gặp trục trặc, giảm thiểu thời gian ngừng máy.
- Làm việc trong môi trường động: Khi cánh tay robot hoạt động trong không gian chung với con người hoặc các thiết bị di động khác, RL kết hợp với cảm biến và thị giác máy tính cho phép chúng học cách tránh va chạm một cách an toàn và hiệu quả. Điều này đặc biệt quan trọng đối với robot cộng tác (cobots).
Tối ưu hóa hiệu suất và hiệu quả năng lượng:
RL cung cấp cơ hội để tối ưu hóa hiệu suất hoạt động và hiệu quả năng lượng của cánh tay robot, vượt xa các phương pháp điều khiển truyền thống.

- Điều khiển chuyển động tối ưu: Robot có thể học cách thực hiện các chuyển động mượt mà, nhanh chóng nhất hoặc tiết kiệm năng lượng nhất để hoàn thành một tác vụ. Điều này có thể bao gồm việc tìm ra quỹ đạo tối ưu để di chuyển bộ phận gắp hoặc giảm thiểu rung động.
- Cân bằng tải và lập lịch trình: Trong một hệ thống có nhiều cánh tay robot, RL có thể được sử dụng để tối ưu hóa việc phân chia công việc (cân bằng tải) và lập lịch trình hoạt động giữa các robot để đạt được thông lượng tối đa của dây chuyền sản xuất tự động.
3. Lợi Ích Của Việc Triển Khai Robot Học Tăng Cường Cho Cánh Tay Robot
Việc triển khai Robot học tăng cường mang lại nhiều lợi ích chiến lược và vận hành đáng kể cho cánh tay robot, giúp chúng trở nên thông minh và linh hoạt hơn.
Nâng cao khả năng tự chủ và thích nghi:
RL là yếu tố then chốt nâng cao khả năng tự chủ và thích nghi của robot, giảm đáng kể sự phụ thuộc vào con người.
- Giảm sự phụ thuộc vào lập trình thủ công: Thay vì lập trình chi tiết từng kịch bản và điều kiện cho robot, RL cho phép cánh tay robot tự học từ kinh nghiệm tương tác. Điều này giải phóng lập trình viên khỏi công việc tốn thời gian và dễ lỗi.
- Xử lý các tác vụ chưa từng gặp: Nhờ khả năng học hỏi và khái quát hóa, robot được huấn luyện bằng RL có thể ứng phó hiệu quả với các tình huống mới hoặc bất ngờ mà chúng chưa từng được lập trình sẵn, tăng cường sự mạnh mẽ và linh hoạt của hệ thống.
Cải thiện hiệu suất và chất lượng:
RL góp phần cải thiện đáng kể hiệu suất và chất lượng hoạt động của robot, tối ưu hóa các quy trình sản xuất.
- Tối ưu hóa các tham số vận hành: Robot có thể tự tìm ra các thiết lập tối ưu cho các tham số vận hành (ví dụ: tốc độ, lực, quỹ đạo) mà con người khó có thể xác định thủ công. Điều này dẫn đến hiệu quả cao hơn và tiết kiệm tài nguyên.
- Độ chính xác và nhất quán cao: Bằng cách liên tục học và điều chỉnh, robot có thể duy trì độ chính xác và nhất quán cao trong các tác vụ lặp đi lặp lại, ngay cả trong điều kiện môi trường có biến đổi nhỏ, đảm bảo chất lượng sản phẩm đầu ra.
Giảm thời gian và chi phí triển khai:
RL có tiềm năng giảm đáng kể thời gian và chi phí triển khai hệ thống robot, đặc biệt đối với các ứng dụng phức tạp.
- Triển khai nhanh hơn: Việc giảm bớt nhu cầu lập trình và tinh chỉnh thủ công cho từng tác vụ hoặc môi trường cụ thể giúp rút ngắn đáng kể thời gian triển khai các ứng dụng robot mới.
- Giảm chi phí vận hành: Bằng cách tối ưu hóa hiệu quả năng lượng, giảm thiểu lỗi và sự cố, cũng như giảm thời gian ngừng máy (downtime), RL có thể giúp giảm đáng kể chi phí vận hành tổng thể của hệ thống robot trong dài hạn.
Đẩy mạnh đổi mới trong Nhà máy thông minh:
RL là động lực thúc đẩy đổi mới trong Nhà máy thông minh, mở ra những cánh cửa mới cho ứng dụng robot.
- Phát triển ứng dụng robot mới: Khả năng của RL cho phép robot học các tác vụ phức tạp và không định trước mở ra cơ hội phát triển các ứng dụng robot mới mà trước đây được coi là quá khó hoặc không thể tự động hóa.
- Tích hợp sâu hơn với Công nghiệp 4.0: Khi cánh tay robot trở nên thông minh và tự chủ hơn nhờ RL, chúng sẽ trở thành trung tâm của các hệ thống sản xuất tự động tích hợp sâu hơn với các công nghệ Công nghiệp 4.0 như IoT, Big Data và AI, tạo nên một quy trình sản xuất linh hoạt và phản ứng nhanh.
4. Thách Thức và Triển Vọng Của Robot Học Tăng Cường Trong Sản Xuất
Mặc dù Robot học tăng cường mang lại nhiều tiềm năng, nhưng nó cũng đối mặt với nhiều thách thức đáng kể, đòi hỏi các hướng nghiên cứu và phát triển để hiện thực hóa toàn bộ tiềm năng.
Thách thức hiện tại
Các thách thức hiện tại của RL chủ yếu liên quan đến yêu cầu về tài nguyên, an toàn và khả năng chuyển giao từ môi trường mô phỏng sang thực tế.
- Thời gian và tài nguyên đào tạo: Các thuật toán RL thường đòi hỏi một lượng lớn dữ liệu tương tác và thời gian tính toán đáng kể (thường là hàng triệu hoặc tỷ bước mô phỏng) để học được các hành vi phức tạp. Điều này đòi hỏi chi phí tính toán cao và có thể là rào cản đối với các doanh nghiệp.
- An toàn trong quá trình học: Trong giai đoạn robot “thử và sai” trong môi trường thực tế, luôn tiềm ẩn rủi ro về hư hại thiết bị hoặc gây mất an toàn cho nhân sự. Việc đảm bảo an toàn là một thách thức lớn khi triển khai RL trực tiếp trên các robot công nghiệp đắt tiền.
- Khả năng giải thích (Interpretability): Các mô hình RL thường là “hộp đen”, khó hiểu được lý do tại sao robot lại đưa ra một quyết định hoặc thực hiện một hành động cụ thể. Điều này gây khó khăn trong việc gỡ lỗi hoặc tinh chỉnh hệ thống.
- Khoảng cách mô phỏng-thực tế (Sim-to-Real Gap): Kết quả học từ môi trường mô phỏng (simulation) thường khó có thể chuyển giao hoàn toàn và hiệu quả sang môi trường vật lý (real world) do sự khác biệt về vật lý, ma sát, độ trễ cảm biến, v.v. Thu hẹp khoảng cách này là một lĩnh thức nghiên cứu quan trọng.
Các hướng giải quyết và triển vọng:
Để vượt qua những thách thức hiện tại, các nhà nghiên cứu đang phát triển nhiều hướng tiếp cận mới, mở ra triển vọng tươi sáng cho RL trong robot học.
- Học tăng cường dựa trên mô hình (Model-based RL): Thay vì chỉ học từ trải nghiệm, các phương pháp này kết hợp việc xây dựng một mô hình của môi trường, cho phép robot “suy nghĩ trước” và lập kế hoạch hiệu quả hơn, giảm đáng kể số lượng tương tác thực tế cần thiết.
- Học tăng cường ngoại tuyến (Offline RL): Hướng nghiên cứu này tập trung vào việc học từ một tập dữ liệu đã thu thập sẵn (ví dụ: dữ liệu từ các lần vận hành trước, dữ liệu từ con người) mà không cần tương tác trực tiếp với môi trường. Điều này giúp giảm thiểu rủi ro an toàn và chi phí triển khai.
- Học từ biểu diễn (Representation Learning) và Học chuyển giao (Transfer Learning): Các kỹ thuật này giúp robot học các biểu diễn dữ liệu hiệu quả và chuyển giao kiến thức đã học từ một nhiệm vụ hoặc môi trường này sang một nhiệm vụ hoặc môi trường khác, tăng tốc quá trình học cho các nhiệm vụ mới.
- Kết hợp RL với các phương pháp AI khác: Việc tích hợp RL với các công nghệ AI khác như Thị giác máy tính (Computer Vision) để nhận dạng và theo dõi đối tượng, hoặc AI để lập kế hoạch cấp cao, sẽ tạo ra các hệ thống robot thông minh và mạnh mẽ hơn.
- RL cho Robot cộng tác (Cobots): RL đặc biệt tiềm năng trong việc giúp robot cộng tác học cách tương tác an toàn và hiệu quả với con người trong không gian làm việc chung. Điều này cho phép cobots thích nghi với các hành vi của con người mà không cần lập trình trước, mở ra các ứng dụng mới trong sản xuất linh hoạt.
5. Kết Luận
Tóm lại, Robot học tăng cường đang cách mạng hóa cách cánh tay robot học và thực hiện các nhiệm vụ trong môi trường sản xuất công nghiệp, từ các tác vụ gắp đặt đơn giản đến các quy trình lắp ráp phức tạp. Bằng cách cho phép robot tự học thông qua thử và sai. RL mở ra kỷ nguyên của cánh tay robot thực sự thông minh, tự chủ và thích nghi, giảm thiểu đáng kể nhu cầu lập trình thủ công tốn kém và mất thời gian. Mặc dù RL vẫn còn đối mặt với những thách thức đáng kể liên quan đến tài nguyên tính toán, an toàn trong quá trình học và khoảng cách mô phỏng-thực tế, nhưng những tiến bộ không ngừng trong nghiên cứu và sự kết hợp với các công nghệ AI khác đang dần tháo gỡ các rào cản này.