
Điện toán đám mây
Phân tích Nguyên nhân Gốc rễ (RCA) với Dữ liệu Đám mây trong Sản xuất Công nghiệp

Trong sản xuất công nghiệp hiện đại, quy trình phức tạp khiến việc xác định nguyên nhân gốc rễ của lỗi và sự cố trở nên khó khăn. Phân tích nguyên nhân gốc rễ (RCA) dựa trên nền tảng dữ liệu đám mây giúp doanh nghiệp chuyển từ phản ứng bị động sang dự đoán chủ động, nhờ hợp nhất Big Data từ các hệ thống IIoT và OT/IT vào một kiến trúc dữ liệu thống nhất. Giải pháp này mang lại minh bạch dữ liệu, tối ưu hiệu suất vận hành và hỗ trợ bảo trì dự đoán. Bài viết sẽ phân tích cách ứng dụng Data Platform Cloud trong RCA, từ kiến trúc dữ liệu đến các phương pháp nâng cao sử dụng AI/ML và phân tích thời gian thực, hướng tới mục tiêu nâng cao năng suất và duy trì lợi thế cạnh tranh.
1. Phân tích Nguyên nhân Gốc rễ (RCA) là gì và Tại sao phải Chuyển lên Đám mây?
1.1. Định nghĩa và Mục tiêu của RCA trong Sản xuất
Phân tích nguyên nhân gốc rễ (RCA) là một phương pháp luận có hệ thống được áp dụng để xác định nguyên nhân nền tảng và sâu xa nhất của một vấn đề, sự cố, hoặc sai lệch hệ thống trong quy trình Sản xuất công nghiệp. Phương pháp luận này tránh việc chỉ xử lý các triệu chứng bề mặt, mà thay vào đó đào sâu vào cốt lõi của vấn đề thông qua các kỹ thuật như “5 Whys” hoặc “Fault Tree Analysis”.
Mục tiêu cuối cùng của RCA là giảm thiểu sự cố tái diễn và ngăn chặn các lỗi tương tự xảy ra trong tương lai, giúp doanh nghiệp tiết kiệm chi phí vận hành và nâng cao đáng kể hiệu suất OEE (Overall Equipment Effectiveness) tổng thể. Việc áp dụng RCA cần thiết để đạt được mức độ Chất lượng dữ liệu và tính ổn định cao trong môi trường sản xuất.
1.2. Hạn chế của RCA truyền thống (On-premise)
RCA truyền thống tại chỗ (on-premise) thường xuyên phải đối mặt với nhiều hạn chế cố hữu, làm giảm hiệu quả và tốc độ phản ứng đối với các sự cố phức tạp. Các hạn chế này ngăn cản các nhà phân tích tiếp cận bức tranh toàn cảnh về dữ liệu và gây khó khăn cho việc xác định nguyên nhân chính xác. RCA truyền thống không thể xử lý khối lượng Big Data phát sinh từ các cảm biến IIoT hiện đại một cách hiệu quả, dẫn đến việc phân tích bị giới hạn trong các mẫu dữ liệu nhỏ và không đầy đủ.
Các vấn đề chính của RCA truyền thống bao gồm:
- Phân mảnh dữ liệu: Dữ liệu OT (Operational Technology) từ các hệ thống điều khiển như SCADA và PLC hoạt động độc lập với dữ liệu IT (Information Technology) từ các hệ thống kinh doanh như ERP và MES, gây ra sự đứt gãy trong chuỗi thông tin.
- Thiếu khả năng xử lý Big Data: Hạ tầng tại chỗ không có đủ sức mạnh tính toán và Khả năng mở rộng để xử lý dữ liệu luồng tốc độ cao (Thời gian thực) từ hàng triệu cảm biến IIoT, dẫn đến bỏ sót các sự kiện quan trọng.
- Tốn kém và thiếu linh hoạt: Chi phí đầu tư (CapEx) vào phần cứng và bảo trì rất cao, đồng thời việc mở rộng quy mô (scale-out) khi nhu cầu dữ liệu tăng lên rất chậm và phức tạp.
- Thời gian phản hồi chậm: Quy trình thu thập, tích hợp, và chuẩn hóa dữ liệu diễn ra thủ công, kéo dài thời gian phân tích, làm giảm hiệu quả can thiệp Thời gian thực.
1.3. Lợi thế của Dữ liệu Đám mây trong RCA
Nền tảng Cloud Data Platform đem lại những lợi thế chiến lược vượt trội, biến đổi Phân tích nguyên nhân gốc rễ (RCA) thành một quy trình chủ động và toàn diện. Nền tảng này cho phép doanh nghiệp giải quyết các hạn chế về Khả năng mở rộng và tính linh hoạt mà RCA truyền thống không thể đáp ứng. Data Platform Cloud giúp hợp nhất tất cả các nguồn dữ liệu vào một Kiến trúc dữ liệu duy nhất.
Sức mạnh tính toán vô hạn của Cloud đảm bảo khả năng xử lý Big Data và phân tích Thời gian thực tức thì, tăng cường khả năng phát hiện lỗi nhanh chóng. Hơn nữa, mô hình Chi phí linh hoạt (OpEx) tạo điều kiện cho việc thử nghiệm các phương pháp RCA mới mà không cần đầu tư ban đầu lớn.
2. Kiến trúc Dữ liệu Đám mây Tối ưu cho RCA
Việc xây dựng một Kiến trúc dữ liệu mạnh mẽ là điều kiện tiên quyết để tối ưu hóa Phân tích nguyên nhân gốc rễ (RCA) bằng Dữ liệu đám mây. Kiến trúc dữ liệu này phải được thiết kế để xử lý hiệu quả các luồng dữ liệu tốc độ cao và đảm bảo Chất lượng dữ liệu ở mọi giai đoạn, tạo ra nền tảng vững chắc cho các mô hình AI/ML.
2.1. Tầng Thu thập Dữ liệu Luồng (Ingestion)
Tầng Thu thập Dữ liệu Luồng (Ingestion) đóng vai trò là cửa ngõ đầu tiên và quan trọng nhất, đảm bảo dữ liệu Thời gian thực từ các thiết bị IIoT và hệ thống OT được thu thập với độ trễ cực thấp. Tầng này cần ưu tiên các dịch vụ Cloud Native Services được thiết kế để xử lý luồng dữ liệu lớn và liên tục. Các công cụ như Amazon Kinesis, Google Pub/Sub, hoặc Azure Event Hubs/Kafka là các lựa chọn hàng đầu, giúp thu thập hàng triệu sự kiện từ các cảm biến mỗi giây.
Kỹ thuật cốt lõi ở tầng này là xử lý dữ liệu luồng (stream processing) nhằm mục đích chuẩn hóa định dạng, lọc nhiễu ban đầu, và nén dữ liệu trước khi chuyển tiếp. Việc đảm bảo tính toàn vẹn của dữ liệu ở giai đoạn này là rất quan trọng để duy trì Chất lượng dữ liệu cho RCA.

2.2. Tầng Lưu trữ Dữ liệu Thô (Data Lake)
Data Lake là một kho lưu trữ tập trung và quy mô lớn, có nhiệm vụ giữ lại tất cả dữ liệu Big Data ở định dạng gốc, bao gồm dữ liệu logs, các chỉ số cảm biến, và dữ liệu phi cấu trúc như hình ảnh/video. Nền tảng lưu trữ Object Storage chi phí thấp như Amazon S3, Google Cloud Storage (GCS), hoặc Azure Blob Storage là các thành phần chủ chốt của tầng này.
Đặc điểm quan trọng nhất của Data Lake là nguyên tắc Schema-on-read, cho phép nhà phân tích linh hoạt truy vấn dữ liệu mà không cần định hình trước cấu trúc. Mối liên kết giữa Data Lake và Phân tích nguyên nhân gốc rễ (RCA) rất mạnh mẽ, vì nó cung cấp nguồn dữ liệu nguyên thủy, phong phú để huấn luyện các mô hình AI/ML phức tạp. Các mô hình này cần dữ liệu thô, chưa bị xử lý để thực hiện các chức năng như phát hiện điểm bất thường (Anomaly Detection) một cách chính xác.
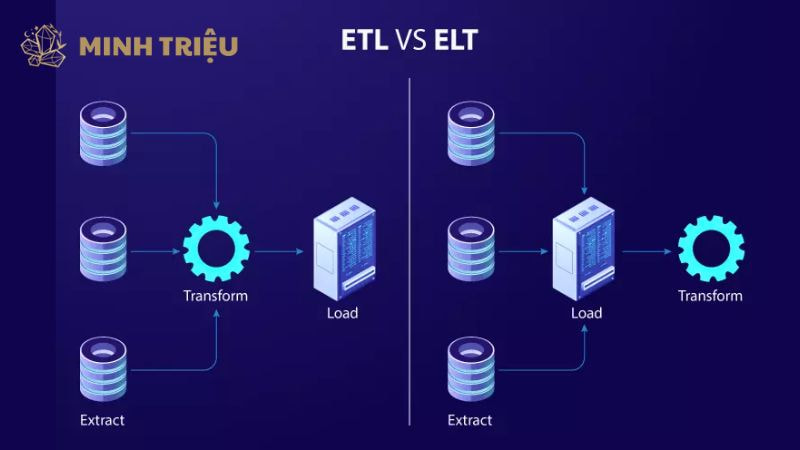
2.3. Tầng Xử lý và Tinh chỉnh (ETL/ELT)
Tầng Xử lý và Tinh chỉnh chịu trách nhiệm chuyển đổi dữ liệu thô và hỗn loạn từ Data Lake thành dữ liệu sạch, có cấu trúc và đáng tin cậy để đưa vào Data Warehouse. Quy trình ETL/ELT (Extract, Transform, Load / Extract, Load, Transform) là bước thiết yếu để làm sạch, chuẩn hóa, và làm phong phú dữ liệu, loại bỏ các giá trị ngoại lai và dữ liệu thiếu sót.
Các công cụ Cloud Native Services như AWS Glue (cho ETL serverless), Google Dataflow, và Azure Data Factory được sử dụng để tự động hóa các pipeline này. Sự liên kết với RCA thể hiện ở việc đảm bảo Chất lượng dữ liệu (Data Quality) cao: dữ liệu đã được tinh chỉnh này giúp các báo cáo BI và các truy vấn RCA truyền thống trở nên chính xác và đáng tin cậy hơn, giảm thiểu rủi ro đưa ra kết luận sai lệch.
3. Các Phương pháp RCA Nâng cao trên Cloud Data Platform
Data Platform Cloud mở ra khả năng ứng dụng các phương pháp Phân tích nguyên nhân gốc rễ (RCA) tiên tiến vượt xa khả năng của các công cụ phân tích truyền thống. Các phương pháp này tận dụng sức mạnh của Big Data và AI/ML để tìm kiếm mối quan hệ ẩn sâu.
3.1. Phân tích Tương quan Lớn (Massive Correlation Analysis)
Phân tích Tương quan Lớn là kỹ thuật sử dụng Data Warehouse quy mô lớn (ví dụ: Google BigQuery, AWS Redshift) để chạy truy vấn trên hàng tỷ bản ghi dữ liệu lịch sử và Thời gian thực. Kỹ thuật này tìm kiếm mối liên hệ phức tạp giữa nhiều yếu tố vận hành khác nhau (như nhiệt độ lò nung, áp suất thủy lực, tốc độ băng chuyền, và lô hàng nguyên vật liệu).
Các công cụ Data Warehouse đám mây thực hiện các phân tích tương quan đa biến này một cách gần như tức thì, cho phép nhà phân tích xác định các pattern dẫn đến sự cố một cách nhanh chóng. Phân tích này tiết lộ các chuỗi sự kiện và sự kết hợp của các điều kiện mà mắt thường không thể thấy, cung cấp thông tin chi tiết quan trọng cho Phân tích nguyên nhân gốc rễ (RCA).
3.2. RCA tự động bằng AI/ML
Việc tích hợp AI/ML đem lại khả năng tự động hóa và dự đoán cho Phân tích nguyên nhân gốc rễ (RCA), chuyển đổi RCA từ một quy trình phản ứng sang chủ động. Các mô hình Machine Learning (ML) có thể được huấn luyện trên dữ liệu lịch sử để tự động gắn nhãn và phân loại các loại lỗi khác nhau. Đặc biệt, AI/ML sử dụng các thuật toán học không giám sát, như phát hiện điểm bất thường (Anomaly Detection), để sàng lọc dữ liệu Thời gian thực từ IIoT và phát hiện sự kiện bất thường trước khi chúng trở thành lỗi nghiêm trọng.
Các ứng dụng chính của AI/ML trong RCA bao gồm:
- Phát hiện Bất thường Tiên lượng: Phát hiện sự thay đổi nhỏ trong hành vi máy móc (ví dụ: độ rung tăng nhẹ) cảnh báo sớm về một sự cố sắp xảy ra.
- Phân loại Lỗi Tự động: Sử dụng mô hình Classification để gán nhãn sự cố mới dựa trên các đặc điểm dữ liệu, rút ngắn thời gian điều tra.
- Đề xuất Gốc rễ: Thuật toán AI/ML phân tích hàng nghìn biến số và tự động đề xuất các nguyên nhân gốc rễ có khả năng nhất, cung cấp thông tin đầu vào cho các chuyên gia.
3.3. Xây dựng Data Lineage (Nguồn gốc Dữ liệu)
Data Lineage là một yếu tố cốt lõi trong việc đảm bảo tính minh bạch và Chất lượng dữ liệu cho Phân tích nguyên nhân gốc rễ (RCA). Nó theo dõi và ghi lại toàn bộ hành trình của dữ liệu, từ lúc được tạo ra từ cảm biến OT (nguồn) đến các bước chuyển đổi ETL/ELT, và cuối cùng là báo cáo được sử dụng trong Data Warehouse.
Vai trò của Data Lineage rất quan trọng khi điều tra sự cố: nó cho phép các nhà phân tích xác minh tính toàn vẹn, nguồn gốc, và lịch sử thay đổi của bất kỳ tập dữ liệu nào được sử dụng để đưa ra kết luận RCA. Điều này đảm bảo rằng kết quả RCA không bị ảnh hưởng bởi các lỗi phát sinh trong quá trình xử lý dữ liệu.
4. Ứng dụng Thực tiễn và Lợi ích Kinh doanh
Sự kết hợp giữa RCA và Dữ liệu đám mây mang lại những lợi ích kinh doanh cụ thể và đo lường được, tập trung vào việc tối ưu hóa hiệu suất và giảm thiểu rủi ro trong môi trường Sản xuất công nghiệp.
4.1. Cải thiện Chất lượng Sản phẩm và Giảm Tỷ lệ Phế phẩm
Phân tích nguyên nhân gốc rễ (RCA) dựa trên Cloud cung cấp khả năng phân tích đa chiều giúp các nhà sản xuất xác định chính xác sự kết hợp phức tạp của các biến số vận hành dẫn đến lỗi sản phẩm.
Bằng cách phân tích Big Data từ các lô hàng lỗi, RCA có thể tìm ra sự tương quan giữa các yếu tố như độ ẩm trong kho, nhiệt độ lò nung ở giai đoạn 3, hoặc sự biến thiên nhỏ của tốc độ băng chuyền. Việc xác định các điều kiện tiên quyết gây ra lỗi cho phép doanh nghiệp điều chỉnh ngay lập tức các tham số kiểm soát quá trình sản xuất. Lợi ích trực tiếp là giảm đáng kể tỷ lệ phế phẩm, cắt giảm chi phí sản xuất và tăng cường sự hài lòng của khách hàng.
4.2. Tối ưu hóa Bảo trì Dự đoán (Predictive Maintenance)
RCA đóng vai trò là thành phần quan trọng để tối ưu hóa chương trình Bảo trì dự đoán. RCA không chỉ dừng lại ở việc tìm nguyên nhân gốc rễ của sự cố đã xảy ra, mà còn cung cấp lý do sâu xa tại sao các mô hình dự đoán (Predictive Models) lại đưa ra cảnh báo sai hoặc đúng. Việc này giúp các kỹ sư dữ liệu tinh chỉnh các mô hình AI/ML, cải thiện độ nhạy và độ chính xác của chúng.
Bằng cách phân tích các cảnh báo sai (false positive) hoặc các lỗi không được phát hiện (false negative), RCA đảm bảo rằng các mô hình Bảo trì dự đoán sẽ trở nên đáng tin cậy hơn, giúp kéo dài tuổi thọ thiết bị và giảm thời gian ngừng máy ngoài kế hoạch (downtime). Sự cải thiện này là rất quan trọng trong môi trường sản xuất liên tục.

4.3. Nâng cao Hiệu suất Vận hành (Operational Efficiency)
Phân tích nguyên nhân gốc rễ (RCA) có tác động sâu rộng đến việc nâng cao Hiệu suất Vận hành trên toàn bộ chuỗi giá trị. RCA giúp các nhà quản lý tìm ra gốc rễ của sự kém hiệu quả (bottleneck) trong quy trình sản xuất và Quản lý chuỗi cung ứng. Ví dụ, một sự chậm trễ trong khâu giao hàng có thể được truy ngược về một lỗi trong hệ thống ERP (IT) kết hợp với sự cố cảm biến (OT) tại một nhà cung cấp cụ thể.
Việc sử dụng Dữ liệu đám mây cho phép phân tích tích hợp OT/IT này. Lợi ích cuối cùng là tối ưu hóa Chi phí vận hành (OpEx), tăng cường khả năng đáp ứng của dây chuyền, và củng cố khả năng cạnh tranh tổng thể.
5. Kết luận
Dữ liệu đám mây là công cụ tất yếu để chuyển đổi Phân tích nguyên nhân gốc rễ (RCA) từ một quy trình tốn kém và phản ứng bị động thành một khả năng chủ động, mang lại tri thức sâu sắc và Thời gian thực. Data Platform Cloud giải quyết triệt để các hạn chế của RCA truyền thống bằng cách cung cấp Kiến trúc dữ liệu thống nhất, Chất lượng dữ liệu cao, và sức mạnh Big Data cần thiết cho các mô hình AI/ML. Sự chuyển đổi này giúp các doanh nghiệp Sản xuất công nghiệp không chỉ khắc phục mà còn ngăn chặn các sự cố hệ thống một cách hiệu quả hơn bao giờ hết, củng cố nền tảng cho một tương lai Sản xuất Thông minh bền vững.